
Modern software systems are more distributed, complex, and business-critical than they've ever been. A single misconfigured service can take down an entire platform. Teams are aiming for production readiness, which is the state where your services are secure, reliable, observable, and owned. Production Readiness Reviews (PRRs) are one of the key mechanisms to get there.
This guide covers what production readiness actually means, how PRRs work, why they matter more than ever, a detailed checklist you can adapt for your team, best practices for running effective reviews, and how to move beyond one-time checks toward continuous readiness.
What is production readiness?
Production readiness is the outcome where a service is fully prepared for live, ongoing operational use. When you're production ready, your systems are robust enough to handle real-world traffic, observable enough to debug when things go wrong, secure enough to protect user data, and owned by someone who's accountable when incidents happen.
This is different from product readiness, which focuses on whether your features meet market needs and user expectations. A product can be ready for customers while still being unprepared for the operational realities of running in production.
Production readiness is what bridges that gap. It's both a technical state and a cultural one. The technical side includes monitoring hooks, security scans, load testing, and rollback plans. The cultural side includes clear ownership, documented processes, and the discipline to enforce standards even when launches are under pressure.
What is a Production Readiness Review (PRR)?
A Production Readiness Review is the formalized checkpoint that ensures services meet your readiness standards before launch. Think of it as a structured gate where service owners validate their work against a shared checklist, cross-functional stakeholders review potential risk areas, and criteria are either passed or flagged for follow-up.
In a typical PRR, a service owner walks through their readiness checklist with stakeholders from platform engineering, SRE, security, and sometimes product. They confirm:
Monitoring is in place
On-call coverage is assigned
Security scans are passing
Deployment pipelines are tested
Documentation is complete
When gaps are identified, teams either address them before launch or document an exception with an expiration date and a plan to remediate.
PRRs matter because they provide accountability, repeatability, and shared visibility across teams. Without them, readiness becomes a judgment call, and standards drift as different teams interpret requirements differently. With them, you establish a shared definition of "done" that scales as your organization grows.
Why production readiness matters
Production readiness directly affects business outcomes. When services are prepared for production, customer trust goes up, incidents go down, and developers ship with confidence. When they're not, the fallout is real.
According to Cortex's 2024 State of Production Readiness report, 98% of engineering leaders reported experiencing major fallout from launching services that weren't adequately prepared. The same report found that 66% of leaders cite inconsistent standards across teams as their biggest blocker to achieving readiness at scale.
Here's what production readiness enables:
Improved reliability and uptime: Services that meet readiness standards experience fewer incidents and recover faster when things do go wrong, which increases user trust and reduces churn.
Faster incident response and recovery: When monitoring, ownership, and runbooks are in place before launch, mean time to recovery (MTTR) drops significantly because responders know exactly where to look and who to page.
Scalability and performance: Readiness ensures your systems can scale with business growth by validating performance under realistic load conditions before traffic arrives.
Compliance and audit readiness: When security and compliance checks are baked into readiness rather than bolted on later, you reduce risk and accelerate certifications.
Developer confidence and velocity: Codified standards mean engineers know what's expected, ship faster with fewer surprises, and spend less time in post-launch firefighting mode.
The production readiness checklist
A production readiness checklist should be at the core of any PRR, but it needs to be living and adaptable rather than static. What matters for a customer-facing API is different from what matters for an internal batch job. Your checklist should be tailored to the type of service being launched while still maintaining organizational consistency.
The following categories represent common elements teams should validate before going live. Each includes specific actions, examples, and ways Cortex can help automate or streamline the validation process.
Security and compliance checks
Security and compliance need to be baked into readiness rather than treated as an afterthought. When teams skip security checks to hit a launch deadline, they create technical debt that often becomes a crisis months later during an audit or breach.
Before launch, teams should validate:
Secrets management: Ensure API keys, credentials, and tokens are stored in a secrets manager, not hardcoded in repos.
Dependency scans: Run vulnerability scans on all dependencies and address critical CVEs before deploying.
Access controls: Verify that only authorized users and services can access production resources.
Data encryption: Confirm that sensitive data is encrypted both at rest and in transit.
Compliance validation: Check that the service meets relevant regulatory requirements (GDPR, HIPAA, SOC 2, etc.).
Cortex integrates with existing security scanners and compliance tools to automatically surface issues in the readiness process. Instead of manually verifying that scans have run or that vulnerabilities are within acceptable thresholds, these checks become part of your production readiness scorecard, updated continuously as new scans complete.
Observability and monitoring in place
Readiness requires visibility into how systems behave once they're live. If you don't have monitoring in place before launch, you're flying blind the moment something goes wrong.
Teams should confirm:
Logging: Critical application events, errors, and requests are logged with enough context to debug issues.
Monitoring: Key performance indicators (latency, error rate, throughput) are tracked and visible in dashboards.
Alerting: Actionable alerts are configured for system anomalies, with clear thresholds that trigger pages to on-call engineers.
On-call coverage: An on-call rotation is assigned and documented so incidents route to the right people.
Runbook integration: Alerts link to runbooks that explain how to respond, reducing time spent searching for context during incidents.
Cortex can verify that monitoring hooks and on-call ownership are in place through integrations with tools like Datadog, PagerDuty, and more. When a service is missing alerts or on-call coverage shows gaps, it surfaces automatically in your readiness checklist instead of requiring engineers to manually chase down this information.
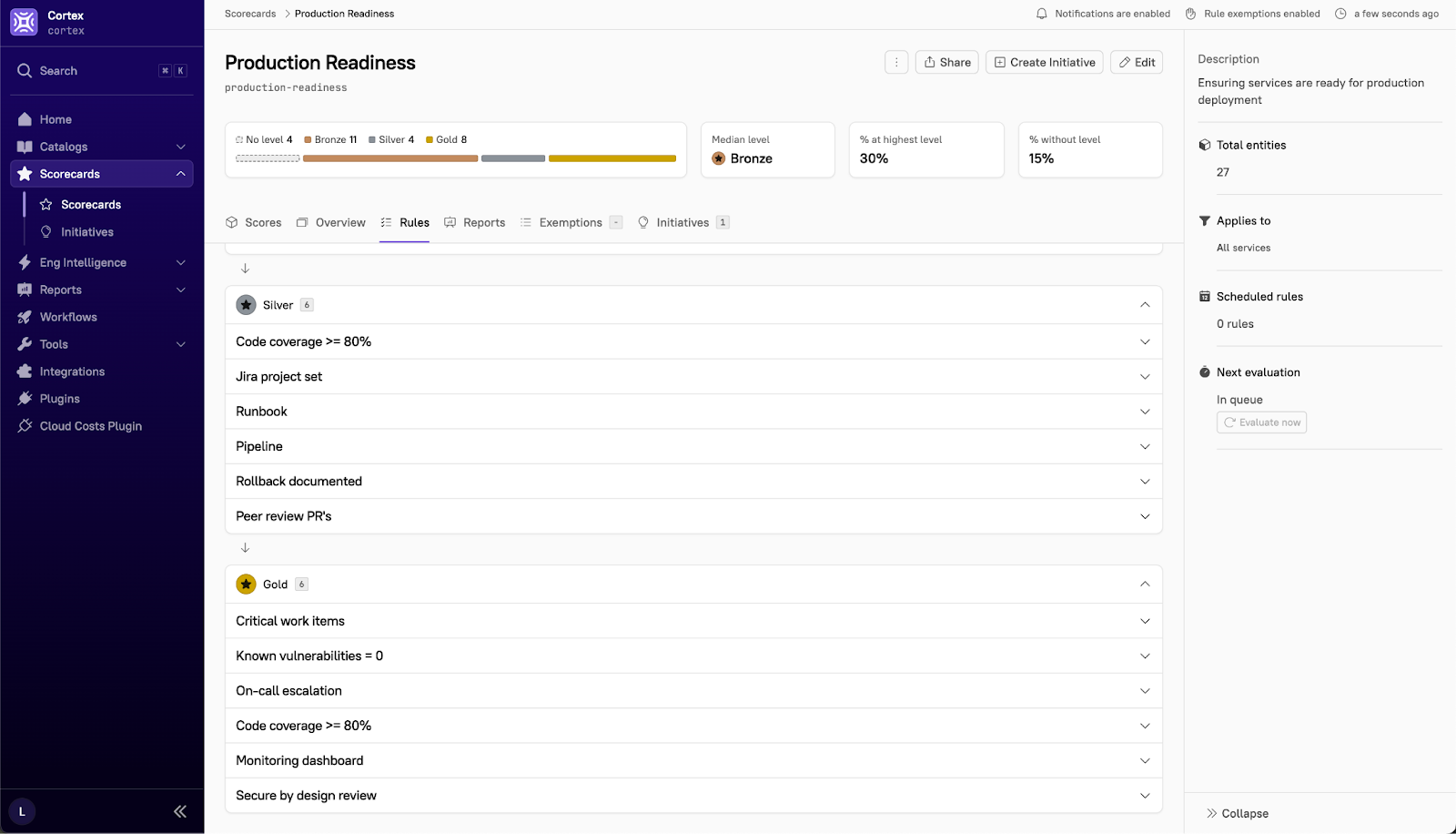
Reliability and SLO validation
Service Level Objectives (SLOs) are a non-negotiable part of readiness. Without them, teams have no shared definition of acceptable performance, and incidents become subjective debates about whether a system is "working" or not.
Before going live, validate:
SLOs defined: Establish clear SLOs for latency, error rate, and availability based on business requirements.
Error budgets calculated: Determine how much failure is acceptable within your SLO constraints.
Failure mode testing: Run chaos experiments or failure injection tests to understand how the system behaves when dependencies fail.
Redundancy and failover: Confirm that redundancy mechanisms are in place and tested, so single points of failure don't take down the entire service.
Consider the example of a payment processing service that launched without load testing its database connection pool. Under normal traffic, everything looked fine. During a Black Friday sale, the connection pool maxed out, transactions started failing, and the team had no error budget or SLO to guide their response. The incident lasted hours because no one had validated reliability assumptions before launch.
Scalability and performance testing
Performance issues discovered in production are expensive and embarrassing. Validating performance under real-world conditions before launch is one of the highest-value activities in a production readiness review.
Teams should conduct:
Load testing: Simulate expected traffic patterns to understand how the service handles realistic load.
Capacity planning: Validate that infrastructure can handle growth projections for the next 6-12 months without manual intervention.
Auto-scaling validation: Test that auto-scaling policies trigger correctly under load and don't over-provision resources unnecessarily.
Stress testing: Push the system beyond expected limits to find breaking points and understand degradation behavior.
Scaling failures directly affect customer trust and revenue. A poorly optimized API that slows down during peak usage drives users to competitors. An e-commerce checkout flow that times out under Black Friday traffic leaves money on the table.
Deployment pipelines and rollback plans
Release pipelines and rollback safety nets are essential for confidence in production. If you can't deploy safely or roll back quickly when something goes wrong, you'll hesitate to ship, which slows down the entire organization.
Readiness requires:
CI/CD pipeline validation: Confirm that automated tests run in CI and deployments follow a consistent, documented process.
Automated deployments: Ensure deployments can be triggered without manual SSH access or runbook-driven shell commands.
Rollback strategy: Test that rollbacks work and can be executed within your MTTR target.
Disaster recovery plan: Document backup and restore procedures, and rehearse them periodically to ensure they actually work.
Cortex can pull in data from CI/CD systems like GitHub Actions, CircleCI, or Jenkins to confirm that pipelines, rollback strategies, and test coverage meet your standards. This reduces the risk of overlooking deployment readiness because it's automatically validated rather than manually checked.
Ownership and on-call documentation
Clear ownership prevents finger-pointing during incidents and ensures someone is accountable for maintaining the service over time. Without it, services become orphaned, technical debt accumulates, and no one knows who to page when things break.
Teams should document:
Service owner: Identify a designated owner or owning team responsible for the service's health and roadmap.
On-call assignments: Establish an on-call rotation with clear coverage and escalation paths.
Escalation policies: Define who to escalate to when the primary on-call engineer is unavailable or the issue is beyond their scope.
Ownership sync: Ensure ownership information is synced with your identity provider so it stays accurate as people change roles.
This isn't just an operational requirement. It's a cultural one. When teams know who owns what, they're more likely to maintain high standards, respond quickly to incidents, and invest in long-term improvements rather than accumulating shortcuts.
Runbooks and supporting documentation
Runbooks are critical for both incident response and onboarding. When incidents happen, responders need clear instructions for common fixes. When new engineers join the team, they need context on how services work and how to debug them.
A good runbook includes:
Common failure scenarios: Document known failure modes and how to respond to them.
Step-by-step remediation: Provide clear, actionable steps for resolving incidents rather than vague guidance like "restart the service."
Debugging tips: Include useful commands, log queries, and dashboards that help narrow down issues quickly.
Service context: Explain what the service does, its dependencies, and its blast radius if it goes down.
Runbooks reduce MTTR and smooth knowledge transfer. When someone wakes up at 3 a.m. to respond to a page, they shouldn't have to reverse-engineer the service from scratch to figure out how to fix it.
Ready to see how this works in practice? Take the Cortex product tour to explore how Scorecards automate the validation of your production readiness checklist, or schedule a custom demo to see how teams are using Cortex to enforce standards without slowing down delivery.
Best practices for running effective PRRs
Production Readiness Reviews are only as valuable as the discipline and culture behind them. The goal is not just passing a checklist but building a consistent, scalable readiness process that teams trust and rely on.
Define clear ownership and accountability
Every service must have a designated owner responsible for ensuring it meets readiness standards. Ownership drives accountability, improves decision-making during incidents, and ensures someone is thinking about long-term maintenance rather than just initial launch.
When ownership is unclear or distributed across too many people, services drift. No one feels responsible for updating documentation, addressing technical debt, or ensuring monitoring stays relevant. Defining ownership upfront as part of your PRR prevents this drift and establishes accountability before problems emerge.
Centralize and standardize readiness criteria
Fragmented checklists slow teams down and create inconsistency. When different teams use different standards, some services launch with robust monitoring and security while others ship with gaps. This creates organizational risk and makes it harder to enforce best practices at scale.
According to Cortex's 2024 State of Production Readiness report, 66% of engineering leaders cite inconsistent standards as their biggest blocker to achieving readiness. Centralizing criteria in a single source of truth improves efficiency, ensures consistency, and makes standards easier to update as your organization evolves.
Cortex helps organizations standardize readiness by maintaining a single source of truth for criteria that all teams can reference. Instead of maintaining checklists in spreadsheets or wikis that fall out of date, standards live in Scorecards that automatically validate against integrated tools and surface gaps in real time.
Automate checks wherever possible
Automation reduces human error and saves time. Manual checks are prone to being skipped under deadline pressure or forgotten as team members change roles. Automated checks run consistently, catch drift before it becomes an incident, and free up engineers to focus on higher-value work.
Examples of what can be automated:
Test coverage validation: Automatically check that code coverage meets your threshold before allowing production deployments.
Security scans: Integrate vulnerability scanners that run on every commit and block releases if critical CVEs are detected.
Monitoring setup: Verify that required monitoring dashboards, alerts, and on-call assignments are in place before launch.
SLO compliance: Track SLO adherence over time and surface when services are consuming their error budget too quickly.
Cortex integrations with CI/CD, observability, and incident management tools enable these checks to run automatically. Instead of manually validating that a service has the right monitoring in place, Cortex pulls data from your existing tools and surfaces gaps before they become production issues.
Plan for exceptions and expirations
Exceptions are necessary to avoid blocking launches when circumstances require flexibility. Maybe a service is launching in a limited beta and can afford to ship with temporary gaps. Maybe a critical bug fix needs to deploy immediately and can't wait for full regression testing. Exceptions handle these cases responsibly without compromising long-term standards.
The key is handling them with discipline:
Expiration dates: Set a clear deadline by which the exception must be resolved.
Visibility: Ensure exceptions are documented and visible to leadership, not hidden in spreadsheets.
Follow-up: Track exceptions over time and escalate when deadlines are missed.
Cortex provides an exception-handling workflow with built-in expiration dates. Teams can ship on time while staying accountable for closing gaps after launch, which prevents exceptions from becoming permanent technical debt.
Integrate PRRs into everyday workflows
Readiness shouldn't live in spreadsheets or require context-switching into separate tools. When PRRs are integrated into the tools developers already use, they become part of the workflow rather than an interruption to it.
Examples of integration:
Service catalogs: Embed readiness status directly in your service catalog so teams can see at a glance which services meet standards.
CI/CD pipelines: Block deployments that don't meet readiness criteria, forcing teams to address gaps before shipping.
Dashboards: Surface readiness metrics in dashboards that leadership and platform teams review regularly to understand organizational health.
When readiness is woven into existing workflows, it's easier to maintain and harder to ignore.
Treat readiness as a continuous process, not a milestone
One-time PRRs are insufficient in a world where code, tools, and teams change constantly. A service that was production ready three months ago might no longer be ready if ownership changed, dependencies were upgraded, or monitoring was accidentally removed during a refactor.
According to Cortex's 2024 State of Production Readiness report, 32% of organizations lack a continuous readiness process, which means they're blind to drift until an incident forces them to notice. Continuous readiness means revisiting and validating standards on an ongoing basis rather than only at launch.
Teams can achieve this by:
Scheduling periodic reviews: Revisit readiness for critical services quarterly or after major changes.
Automating continuous validation: Use tools that continuously check alignment with standards rather than requiring manual audits.
Tracking readiness trends: Monitor how readiness scores change over time to understand whether your organization is improving or regressing.
How Cortex helps teams achieve continuous production readiness
Cortex is built to scale readiness beyond checklists and one-off reviews. It centralizes the data, automates the validation, and provides the visibility you need to ensure services stay ready over time.
Here's how Cortex enables continuous production readiness:
Dynamic Scorecards and customizable checklists: Define your readiness criteria once in Scorecards, and Cortex automatically validates services against them using data from integrated tools. As your standards evolve, update the scorecard and all services are re-evaluated instantly.
Integrations with CI/CD, observability, and incident management tools: Cortex connects to over 50 tools including GitHub, Datadog, PagerDuty, SonarQube, and more. These integrations automatically validate criteria like test coverage, monitoring setup, on-call assignments, and SLO compliance without requiring manual checks.
Exception handling with expirations: When teams need to ship with temporary gaps, Cortex tracks exceptions with built-in expiration dates. This drives accountability without blocking launches unnecessarily, and surfaces when exceptions are approaching their deadline.
Dashboards and reporting for visibility: Cortex provides dashboards that give leadership, platform teams, and compliance stakeholders real-time visibility into which services meet standards and which need attention. This makes readiness measurable and reportable rather than subjective.
Initiatives and benchmarks to track progress: Use Initiatives to track readiness improvements across teams and services. Set goals, measure progress, and benchmark your organization's maturity over time to ensure continuous improvement.
Production readiness is no longer a one-time milestone. It's a continuous discipline that requires automation, integration, and visibility to scale. Cortex makes it possible to enforce standards without slowing down developers, maintain readiness as services evolve, and prove to leadership that your engineering organization is ready for what's next.
Get started for free or book a demo to see how Cortex can help your team achieve continuous production readiness.


