Codify and enforce standards
Define what good looks like for production readiness, security, AI adoption, and more, then hold every team and agent to it, automatically, with Scorecards.

“We've completed three large engineering-wide initiatives. Each one landed faster than the one before, setting a really high bar for us as a team.”
Stuart Ross
Senior Engineering Manager
Don't let AI escape your standards
As code becomes infinite, the risk of standards slipping grows with every commit. Define exactly what "AI-ready" means: ownership, test coverage, security practices, prompt hygiene. Then verify it automatically, on every service.
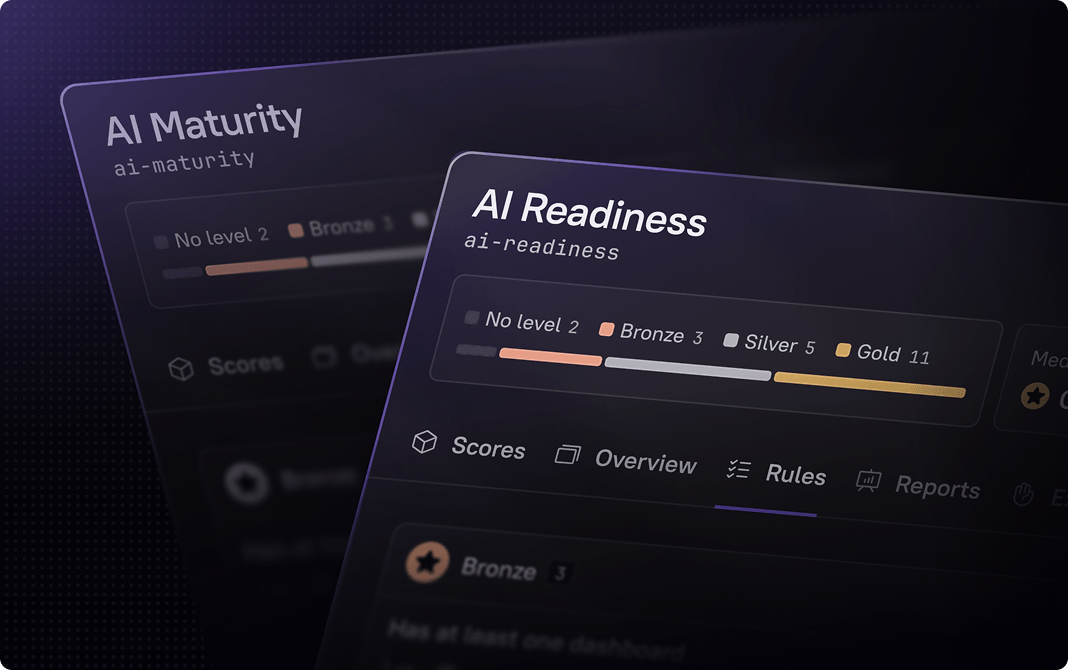
Automatically fix gaps & meet targets for key initiatives
Create golden paths for developers & agents to fix gaps and transform standards into real outcomes by setting clear goals and target dates for critical initiatives. Cortex keeps teams accountable so improvements happen on your timelines.

Track progress and report with confidence
Cortex monitors your org against your standards continuously and surfaces the insights you need for your organization to operate as one. Catch gaps as they happen, with the context to act on it.

Popular Scorecards
Build any Scorecard in minutes – from production readiness to security compliance to AI maturity. With data pulled automatically from your existing tools, it’s easy to define standards, track progress, and drive improvement across teams.
AI Readiness
Establish the foundations for safe AI adoption with strong testing, clear ownership, and secure CI/CD processes. Use Cortex to enforce readiness before rolling out AI tools.


AI Readiness

AI Maturity

Production Readiness

Security compliance

Migration & modernization

Operationalize DORA
AI Readiness
Establish the foundations for safe AI adoption with strong testing, clear ownership, and secure CI/CD processes. Use Cortex to enforce readiness before rolling out AI tools.
Insights and case studies
Subscribe to our blog and be the first to know about the latest updates, features in Cortex.



