
Google has had an outsized impact on the world, from its unrivaled search engine to its expansion into a range of customer-focused services. It would be difficult to make an impact of this magnitude without also leading the way in the software development industry. One of its biggest contributions to the community is a set of principles known as site reliability engineering or SRE.
Today, site reliability engineers are in high demand across the industry, as SRE practices have seen enormous success across organizations. But what exactly is SRE, and does your company need it? Read this article to find out.
What is SRE?
Site reliability engineering is founded on certain principles and practices that aid software developers in building reliable and scalable applications. It centers around the idea of using software and automation to perform operations tasks.
SREs divide their time between carrying out operations tasks such as testing production environments, applying patches manually, and writing code to automate such tasks. Because site reliability engineering is focused on the latter, they develop those solutions for the company to use in the long term.
SRE teams work with development teams to define service level indicators, service level objectives, and error budgets for the applications they build. These metrics and tools help teams understand how reliable their services should be for meeting customer needs.
Understanding the role of SRE in software development
For Google’s Benjamin Treynor Sloss, “SRE is what happens when you ask a software engineer to design an operations team.” Site reliability engineering has emerged from a need to resolve the tension between development and operations teams. In most companies, developers are eager to write new features and ship them off quickly. Operations teams, on the other hand, are focussed on the overall health and reliability of the application. Their job is to ensure new features don’t break the software. This inevitably creates a certain level of disagreement among these teams. The principles of site reliability engineering encourage developers to take a different, more operations-friendly approach to their work, helping bridge the divide between the two teams. Doing so is ultimately beneficial from a business perspective, as it instills a culture of prioritizing reliability across the organization, which directly impacts the quality of the software built.
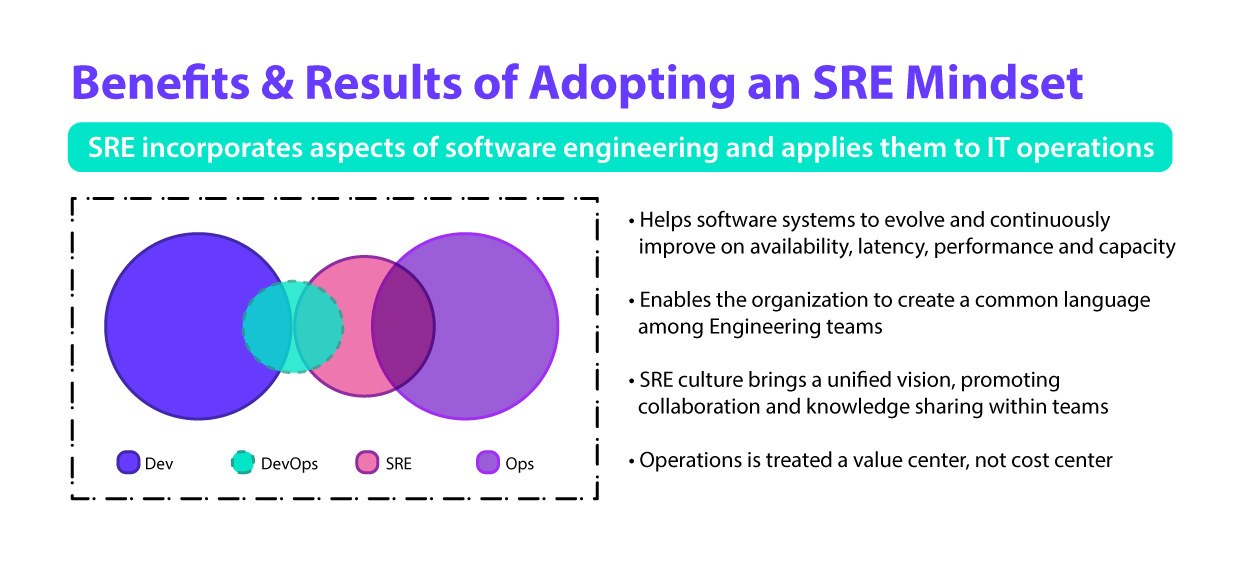
It will come as no surprise, then, that SRE is closely related to the DevOps philosophy. It serves as an implementation of DevOps, offering more concrete guidance to companies that wish to mold their developer culture to prioritize reliability.
The SRE mindset should be adopted across your company, even if you choose to hire engineers specifically for that purpose. Hiring site reliability engineers, although recommended, is often not viable for all companies, especially smaller ones. Regardless of whether you have a dedicated SRE team, you can’t go wrong with driving SRE principles across the board. It contributes to a culture of responsibility and highlights the importance of striking a balance between pursuing innovation and reliability.
Why is SRE important?
It shouldn’t come as a surprise but reliability is at the center of site reliability engineering practices. Customers must be able to trust and rely on the software if they are going to adopt it long-term. Reliability has become much more important for organizations today because they have started to realize the dollar value of their applications being stable and up and running. The amount of time, resources, and effort it takes to build software is significant, so if your services are down, you are losing hundreds of thousands of dollars per minute. This trend is observed across outages, whether enterprise software and data centers experience them or consumer applications. In addition to losing money, companies are also faced with losses in employee morale.
At the same time, developers are stretched thin thanks to the pressures that come with the expectation of rapid product and feature development. On top of that, much of the onus for thinking about reliability naturally falls on the engineers. In small companies especially, the developers are the ones that are juggling various responsibilities, from handling the infrastructure to setting up the cloud platform. Eventually, if matters get complex enough, you feel the need for dedicated teams to handle all that complexity and begin to build them, such as a cloud engineering team.
In the same way, your engineers can start setting up their own monitors and alerts, but eventually, you need some rigor around it. Having somebody spend their entire time thinking about reliability becomes essential. That's where the SRE team comes into the picture. Once you get to a certain scale, you need a team dedicated full-time to establishing your best practices and thinking about reliability. They can support your developers not only by focusing solely on the reliability and functioning of the software but also by encouraging developers to think about these aspects of software development when they write the code.
It is important to instill the SRE mindset in your developers without burdening them with additional duties that go above and beyond their already demanding workloads. This holds true for all companies, whether they have the resources to onboard a separate SRE team or not. Inculcating SRE qualities across the board has a few notable benefits, including:
Automation
Site reliability engineers are primarily tasked with upholding a certain level of reliability of your application, as well as automating operations tasks with code. The Site Reliability Engineering book describes toil as work that has one or more of the following qualities: “manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows.” As a result, the automation of tasks that can be performed without the guidance of a human being is crucial to eliminating toil from the software development process. It streamlines the team’s workflows and bridges the gap between your developers and operations team. Developers find it easier to follow and adopt SRE practices as a result.
Encouraging ownership
Service ownership is vital to maintaining a microservice architecture, as it allows the team to clearly identify and assign responsibility for each microservice. This comes in useful when running incident management and motivates developers to fix complex issues. Having an SRE team dedicated to ensuring ownership or encouraging your existing team to enforce this goes a long way in maintaining transparency and visibility internally.
Building scalable software
SREs are also tasked with making sure that the software is working as it should, and that it can scale. Scalability is essential to any long-term development project, as it reflects the potential for your software to grow and expand its user base without compromising on service quality. In addition to service monitoring, this can involve a certain level of automation when it comes to scaling. Teams without dedicated SREs can strive to prioritize scalability when writing the code itself.
Increased visibility
Clarity is essential for any meaningful undertaking. To this end, SREs rely heavily on monitoring and visibility. It helps them take stock of the situation before thinking about the changes they need to make to the architecture or the team’s workflow. Similarly, adopting an SRE mindset also means tracking relevant metrics like SLIs for every service in the architecture, which ultimately leads to more optimized and efficient processes, such as incident management.
Developing in the cloud
Companies that are looking to migrate their infrastructure to a cloud environment witness a sharp increase in the amount of operations data they have to deal with. SRE is valuable at this juncture, in that it helps automate the operations and maintains a level of reliability despite the increased complexity.
Site reliability engineering also supports faster development in the context of cloud-native applications without forcing the operations teams to compromise on the quality of their work.
How does SRE work in practice?
The SRE team’s charter is to establish a practice and culture of reliability across the organization and define those standards across the board. That comes down to a few different practices.
Understanding the systems in the organization
Without knowing where everything is and how the parts align with each other, there is no way to ensure that the infrastructure functions the way that it should. Having visibility allows SREs to know the lay of the land. This lets them make informed decisions about the next steps that the team needs to take to improve the reliability and scalability of the application.
So, keep track of what you are monitoring already and how. Should you be monitoring anything else? Then decide what to do in case the monitoring system catches something unusual. At this stage, you can also think about the tools you are using, and whether you need to make changes in that regard. Site reliability engineers are ultimately in charge of defining and tracking the right metrics and reporting them to engineering leadership, ensuring end users have a better experience.
Defining the right SRE targets
SRE defined targets and metrics, link your infrastructure and business objectives by offering insights into how reliable the infrastructure is. To get started with these, you must first understand the following three terms:
Service level agreement (SLA): A service level agreement marks a deal between the company and the users regarding the provision of aspects of the software, such as its availability and responsiveness. It is a guarantee given to the users that the application will function in a certain manner and for an agreed-upon duration. Included in an SLA are also the penalties or consequences that the company must face should it fail to meet the terms of the agreement at any point. It helps companies manage users’ expectations and set achievable targets. SLAs are also valuable because they foster trust between both parties and establish communication channels with stakeholders.
Service level objective (SLO): While, SLAs are the externally facing agreements made with end users, service level objectives or SLOs, are the internally facing goals to work toward SLAs. Setting SLOs also gives your team specific targets to work towards and measure the application’s performance against. In a microservices architecture, SLOs play a significant role in keeping service owners accountable so that the services can continue to depend on one another and run smoothly. SLOs are expressed in numerical values and must be clear and simple so as to avoid any confusion. Setting too many SLOs can cause undue stress to developers, so limit your SLOs to a few objectives that are crucial to meeting the requirements of the SLA.
Service level indicator (SLI): A service level indicator is a metric that measures your team’s performance on an SLO. You can measure latency by tracking the time it takes to complete a database query or understand traffic by studying how many requests each API is able to manage simultaneously. Teams must meet or exceed the SLIto be able to comply with the SLA. SLIs, too, must be simple and kept to a minimum. It can be tempting to track everything as an SLI, but that is not recommended as it can complicate matters for your developers instead of helping them stay on track with their goals.
Define a strategy for service level targets and metrics. Here are some best practices to keep in mind:
Centering the user and their experience is a good place to start when setting up your SLAs and SLOs. This also means using simple language when writing them so that the users can understand them easily and you are not faced with misunderstandings in the future.
You can choose to track a variety of performance metrics internally but limit the number of SLOs and SLIs you define. Prioritize the ones that users are directly impacted by. Doing so will result in increased clarity, which is important to both the users as well as your team.
Set up an error budget to account for any issues. This alleviates the burden placed on developers, in addition to giving them the space to make changes and innovate without worrying about the impact of any failures on the users.
Setting up protocols for incident management
Once you have a monitoring system in place, along with a good idea of what your microservices architecture looks like, you can start thinking about how to tackle issues that come up. Usually, this has to do with alerting on-call and incident management and response, i.e., the actions to be taken after you have the monitoring set in place.
From a reliability standpoint, SREs should double down on incident management and put together an appropriate strategy to tackle irregularities in the software. Defining ownership of your services is a good starting point as it streamlines the assignment of duties and the establishment of protocols. Incident management is not optional, given that bugs are bound to surface. Without a proper plan in place, the team risks handling the issue in a chaotic and disorganized way, which is ultimately grossly inefficient.
Set up alerting mechanisms for the metrics you are monitoring. Be sure to prioritize the metrics in line with your SLOs and inform the team regarding the importance of each alert. Incident management tools also centralize all the alerts, which is useful when taking stock of what needs to be looked into immediately, as well as categorizing alerts for in-depth analysis in the future.
Having well-defined processes around incident management can save the team time and effort, which is especially important in the case of outages that usually cost companies a significant amount of money.
Post-incident processes
Once you have your incident management on-call processes in place, it is time to start thinking about post-incident processes. This is something that a lot of engineering teams tend to do haphazardly, usually because the main problem has been resolved. However, giving these processes some thought and implementing a basic plan is instrumental in keeping everyone in the loop and documenting the event for future developers to learn from.
SREs are responsible for error detection and resolution but also for communicating the details to relevant parties. It is then worthwhile to reflect on the team’s documentation practices and communication habits. It is the SRE’s job to open active communication channels with the right stakeholders, including both business and engineering stakeholders, and inform them about the incident, including how severe it was and the steps taken to remedy the situation. Reports are a simple yet effective way to communicate information about the incidents and the response strategy. These can be incident-specific or infrastructure-wide. Stakeholders can evaluate the situation as well as the overall health of the system easily.
SREs also need to determine if a post-mortem is required to ensure that a similar incident does not take place again. The SRE’s job does not end with the resolution of the incident. Instead, they must maintain a certain level of rigor during all stages of the software development process.
Defining best practices for services
As the company ages and your teams have been working on the software for some time, a few do’s and don’ts will naturally emerge. At the same time, it helps to establish these as soon as possible. SREs must take the lead here to evaluate both the workflows as well as the infrastructure to arrive at best practices that can guide the team’s work. Best practices and standards enforce consistency and are indispensable for companies looking to develop scalable software.
The site reliability engineers need not give up their job, but they need to instill an SRE mindset and cultivate a culture amongst developers and other team members. That is one of the responsibilities the SRE must take on after setting up the processes and baselines. How can SREs get people to adopt the monitoring and incident management stacks and run their post-mortems?
 Info credit: devoptopologies.com
Info credit: devoptopologies.com
How do you get the team to care about SRE?
One of the fundamental aspects of being a site reliability engineer is influencing others on the team. Sometimes SREs may find themselves in tricky situations. For example, the CTO will build out the reliability team, but engineering managers do not care about this and go about their work. So SREs have to get the team to care about reliability and scalability, not as an afterthought but as a part of their work.
As an SRE, you should always be thinking about ways in which you can influence the organization to accomplish your charter. You can’t force people into caring about site reliability. Instead, you have to start by making the business case. So clarify the existing status of the company and the application and how SRE is indispensable to improving or fixing it. So, for example, highlight the importance of SRE given that the company risks losing X dollars if reliability is not up to the mark. If you present your case using numbers, people will find it hard to argue against that logic.
Once you have them listening, you want to start thinking about how you can get people to adopt the SRE mindset. This requires working closely with engineering management. Making it a collaborative exercise will be much more effective, as opposed to you trying to bring change single-handedly. You are likely to reach your goals much faster if you make it easy for developers to adopt SRE as part of their practice. Prioritize automation where possible, as well as a gradual learning curve to build a culture of reliability slowly but steadily. The easier you make it for them, the more developers will be open to thinking about SRE.
Another way to slowly integrate site reliability engineering into developers’ workflows is by assigning 5% of operations work to them. Doing so gives them an opportunity to approach the software from a different perspective, which can subsequently inform their coding choices.
You can also choose to delegate more operations-related work to them in the event that the workload is too much for the SRE team to handle. This depletes the resources and manpower in the development team and can also incentivize developers to write better code from the get-go.
How can you get started with SRE?
A microservice catalog tool is a great place to start, whether you are trying to get developers to think about SRE or hiring an SRE team. It is useful to monitor your existing microservices architecture as well as to establish and implement best practices. You can decide on certain rules or standards that all developers must follow when building services and also assign responsibility or hold developers accountable for each service.
Cortex’s service catalog serves as a single pane for developers and site reliability engineers to understand various aspects of each microservice, including ownership details, information about on-call rotations, as well as SLOs. It integrates with your infrastructure and existing tooling so you can access everything you need to know from one place. This is also useful when running incident management, as having the information readily available speeds up the process. Finally, because the microservice catalog tool automates one of the most important aspects of SRE, it becomes all the easier to introduce your developers to it and eventually to site reliability engineering as a set of ideas and practices they must adopt.


