
What startup hasn’t dreamed about going viral and seeing their usage skyrocket overnight? However, when companies are small, teams tend to focus all their energy on improving their product — preparing for a sudden surge of usage is mostly an afterthought. But beware: when success comes knocking, sometimes it brings a sledgehammer and takes down your entire site.
When your site goes viral, you probably want to stay up late celebrating, not frantically trying to revive your crashed app. That’s where load testing comes in. It’s a great thing to be thinking about while your organization is still in the early stages. Investing in your strategy now will only continue to pay off as you grow and scale.
Three things most startups get wrong about load testing
Every engineer knows that load testing is important. Yet, here’s what load testing often looks like at a startup: It’s one engineer’s personal project, where they run scripts on their local machine to test out some theories on what might be slowing the site down. No surprise, then, that teams are often caught unprepared when they finally get that coveted retweet.
If you’re interested in improving your load testing, there are three things you can focus on that most startups simply don’t do:
Testing your entire production setup, rather than isolated services.
Defining clear ownership so that someone is responsible for load testing.
Achieving cultural buy-in within the team so the right actions are taken to improve performance.
Let’s dig deeper into each of these points.
1. Testing your production setup
There are two kinds of load testing. The first type of load testing is about identifying basic bottlenecks. For example, is your application I/O-bound? Is it CPU-bound? Which microservices fail when you hammer them with concurrent requests? This type of load testing can be good for testing out a hunch based on where you’ve seen latency on your site. But with everything being tested in isolation, you don’t get the full picture of their performance in production.
That’s why there’s a need for a second type of load testing that’s production-based. This means seeing testing your entire setup in an environment that resembles production as closely as possible. Here, you’re interested in how the whole system takes on load: What are the dependencies and limitations between upstream and downstream services? How do your SLIs change as you scale up the simulated traffic?
The right SRE tools can help you perform production-based load testing. But there’s another challenge: overcoming the cultural and organizational obstacles that prevent you from taking action on your test results.
2. Defining ownership
While many software engineering functions have a dedicated owner, load testing is one of those gray areas, especially at a startup where there’s no dedicated SRE. Should the QA team handle load testing? Or the cloud infrastructure engineering team? How about DevOps?
If you don’t make a decision about ownership, load testing probably won’t be prioritized — and your on-call engineers will be left cleaning up the mess when services fail in production. Engineering managers can help protect their team from this outcome by making a proactive decision about who will oversee the setup, automation, and reporting on load testing.
Read more about how to drive ownership, especially for your microservices.
3. Achieving buy-in
You can be doing all kinds of automated load testing on your production traffic, but it won’t help if there’s just one engineer on the team who cares about it. (And unfortunately, this is often the case.) If you own load testing at a startup, part of your job is going to be making sure the results have an impact and add value to your team. Here are some suggestions:
Avoid tribal knowledge by creating a single source of truth that the whole team has access to. Make the results objective using clear SLIs that are tied to business goals. (See our tips here.)
Make sure your results are visual and actionable. Whether it’s with alerts or a dashboard, try to avoid the default of outputting your statistics to a lonely database somewhere.
Automate wherever possible. Create a job that runs, say, every 24 hours. Even better if it automatically notifies engineers when their services fail to meet certain criteria. This makes the results objective and takes you out of the process (no one likes to be a nag).
Be careful about gating releases. For example, adding a load testing regression check to your CI/CD pipeline could be too heavy-handed and alienate your team. Perhaps what you really need at this stage is a way to track how your services are generally performing over time (and whether you are regressing).
You’ll find more tips about affecting cultural change in our guide to improving your influence as an SRE.
Using Cortex for load testing
We’ve seen first-hand how some of our customers are using Cortex to scale up their load testing efforts. For example, one customer runs load tests every day and pushes the previous seven days of rolling results to Cortex at all times. As the reporting mechanism, they use a Cortex Scorecard they’ve designated specifically for load testing.
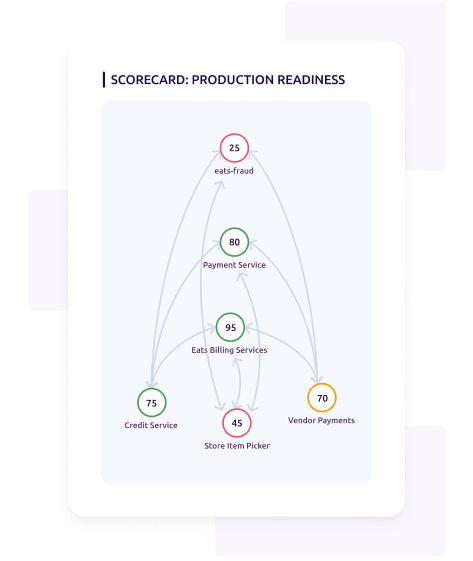
Scorecards are ways to report on service health at a glance. Customers have used Scorecard notifications to set up reports on their load testing results that go straight to the service owners. The SREs can even set new performance goals and track progress using Cortex’s Initiatives feature.
With Scorecards, the whole team has a dashboard for seeing how the system is performing overall. The new Graph View lets you contextually overlay your Scorecard data on the graph of your microservices. This feature is especially useful for a load testing Scorecard: You can easily see all the dependencies and identify bottlenecks at a glance.
 If you want to scale up your load testing efforts as an organization (maybe because your userbase is scaling up) and make this a fully integrated part of your QA and production readiness process — we might be able to help! You can sign up for a free demo of Cortex here.
If you want to scale up your load testing efforts as an organization (maybe because your userbase is scaling up) and make this a fully integrated part of your QA and production readiness process — we might be able to help! You can sign up for a free demo of Cortex here.


