
This article references Cortex as an Internal Developer Portal (IDP).
The internal developer portal was born out of a thesis that quickly proved to be correct: that developers needed a single place to find documentation, understand service ownership, and navigate complex toolchains. In the time since, many engineering teams have discovered they need more than organized information. They need a platform that orchestrates workflows end to end, enforces standards automatically, and gives engineering leaders the data to act on what they find.
Cortex has been building toward this vision for years, adding capabilities that go well beyond what any portal was originally designed to do. As a result, we've expanded our vision to be an end-to-end Engineering Operations Platform – a far more accurate description of what that work has produced for our customers. It's also a more useful frame for any team thinking seriously about what their internal platform needs to become.
When launches are delayed or incidents occur, it’s often due to a breakdown in production readiness. Maybe documentation is outdated. Maybe no one’s on-call. Maybe a critical dependency isn’t even known.
The truth is, production readiness shouldn’t be a manual checklist. Production readiness needs to be as dynamic as the software being evaluated.
In this guide, we’ll explore what production readiness really means, and how to evolve your approach from static reviews to always-on readiness, including a template to get you started.
What is production readiness?
Production readiness means your software is capable of running safely and reliably in a live environment.
A production-ready service:
Has a clear owner and on-call rotation
Has clear visibility against state/performance against org standards
Logs key events and highlights relevant metrics
Is supported by stakeholders across Dev, SRE, Security, and Platform
Handles failure gracefully and recovers predictably
Production readiness directly impacts business outcomes by avoiding costly downtime, protecting user trust, and enabling engineering teams to iterate safely and confidently.
Fewer incidents and faster recovery: Well-prepared services are less likely to fail, and when they do, recovery is quicker due to clear documentation and established procedures.
Increased engineering confidence: Knowing services meet high standards empowers developers to innovate and deploy with greater confidence.
Clearer ownership and on-call accountability: Defined ownership means faster response times and more effective incident management.
Better cross-team alignment (Dev, SRE, Platform): A shared understanding of "ready" fosters collaboration and reduces friction.
Easier compliance and audits: Standardized readiness checks simplify adherence to regulatory and internal governance requirements.
Streamlined onboarding and faster service development: New team members can get up to speed more quickly with well-documented, reliable services.
More reliable, higher quality releases: Ultimately, it leads to better software for your users.
For more background, see We Need to Talk About Production Readiness.
Common production readiness pitfalls to avoid
Even with the best intentions, many engineering organizations fall into common traps that undermine their production readiness efforts.
Manual, labor-intensive workflows
Teams performing production readiness reviews tend to have static checklists and spreadsheets that they check and update manually.
Manual readiness reviews eat up hours of coordination time—TPMs chasing teams in Slack, sending reminders, and asking the same questions over and over. Then comes the spreadsheet wrangling, manually compiling statuses for exec updates that are out of date the moment they’re sent.
Relying on tribal knowledge and static documentation
When crucial information about services lives only in the heads of a few key individuals or in outdated wikis and spreadsheets, it creates significant risk. This tribal knowledge doesn't scale, leads to inconsistencies, and makes onboarding new developers a painful experience.
Inconsistent standards across services or teams
Without a centralized approach, different teams or services may adhere to varying levels of quality and preparedness. This inconsistency makes it difficult to assess overall risk, manage dependencies effectively, and ensure a uniform level of reliability for users.
Lack of visibility and accountability
If you can't see the current state of your services against defined standards, you can't enforce them. A lack of clear ownership and accountability for meeting readiness criteria means that gaps can persist unnoticed until an incident occurs.
Binary, black-and-white model
Traditionally, production readiness is defined in binary terms: ready or not ready, on or off, in production or out.
Checklists are done once, even though the criteria for production readiness can change over time and the standards that determine whether a service passes can change, too. Services that are currently in production might not change even as the standards around them do, meaning services already in production can end up not being production-ready anymore.
Treating readiness as a checkbox instead of a culture
Perhaps the biggest pitfall is viewing production readiness as a one-time gate passed just before launch.
When you only have a checklist, you can never really know whether all your services in production are actually production-ready. The services themselves are changing, but so are your checklists and your broader sense of readiness. At worst, you could end up proceeding with false confidence, causing errors as you introduce new services and strain old dependencies.
True production readiness is a cultural commitment to ongoing excellence, where standards are continuously monitored and maintained throughout the lifecycle of a service.
From Manual Reviews to Always-On Readiness
Historically, production readiness reviews (PRRs) were manual exercises held just before launch—checklist meetings that relied on human intervention, scattered tooling and documentation, and institutional knowledge. They were time-consuming, inconsistent, and prone to oversight.
Today, readiness can be always-on.
With an Internal Developer Portal like Cortex, checks that were once manual can now be automated:
Instead of asking, "Is there an owner?", ownership is automatically assigned and visible.
Instead of manually verifying logging or test coverage, real-time data from your observability and CI/CD tools is pulled into Scorecards.
Instead of waiting for someone to schedule a review, readiness is continuously tracked and surfaced.
This shift from static reviews to continuous visibility means teams can identify and address issues as they happen, not days before release (or worse—after something has already gone out the door).
How Every Team Benefits from Always-On Readiness
Continuous readiness enables everyone across the software delivery lifecycle to work more effectively, with fewer surprises and greater confidence. By making readiness visible, automated, and self-serve, Cortex aligns teams across engineering, operations, and leadership.
Platform Engineering
As the backbone of internal tooling and best practices, platform engineers need visibility and control to enforce consistency at scale. An IDP like Cortex enables platform teams to:
Drive adoption of golden paths and standard templates
Surface fragile, non-compliant services before they cause issues
Roll out platform-wide upgrades (e.g., auth libraries, language versions) faster
Maintain clarity on ownership, even through reorgs
SRE & DevOps
Reliability and operational maturity are non-negotiable for SRE and DevOps teams. Instead of reacting to incidents, always-on readiness helps proactively prevent them. With Cortex, these teams can:
Flag unready services before deployment (missing SLOs, runbooks, alerts)
Prevent high-risk services from going live
Reduce MTTR with clear ownership and context-rich alerts
Improve postmortems by correlating incidents to maturity gaps
Engineering Leaders
Leaders need confidence that systems are healthy and teams are accountable, without micromanaging. Continuous readiness gives them real-time assurance that standards are being met, and that launch risk is low. Cortex helps:
Deliver org-wide visibility into service health and readiness scores
Enable standardization at scale: know what "ready" means for everyone
Build confidence during critical periods (e.g., seasonal spikes, high-risk launches)
Provide proof of maturity for leadership and board-level discussions
TPMs
Technical Program Managers orchestrate cross-functional efforts and need predictable delivery. Always-on readiness eliminates surprises and provides clear checkpoints. Cortex supports TPMs with:
Visibility into progress across teams and initiatives
Deadline enforcement for freezes, upgrades, or security checks
Clear identification of blockers and lagging teams
Clean, accurate reporting for stakeholders
Developers
Developers want to ship features, not hunt down what to do next. Always-on readiness removes guesswork and gives them tools to self-serve, with clarity around what's expected. With Cortex, developers:
No longer guess about ownership, alerts, or documentation
See readiness baked into the development process from Day One
Build with confidence, not chaos
Scorecard Template: Automating Production Readiness
This scorecard is designed to serve as inspiration and a starting point for organizations looking to enforce production readiness standards. While this template includes a set of predefined rules, organizations should customize it to fit their own requirements, infrastructure, and reliability goals.
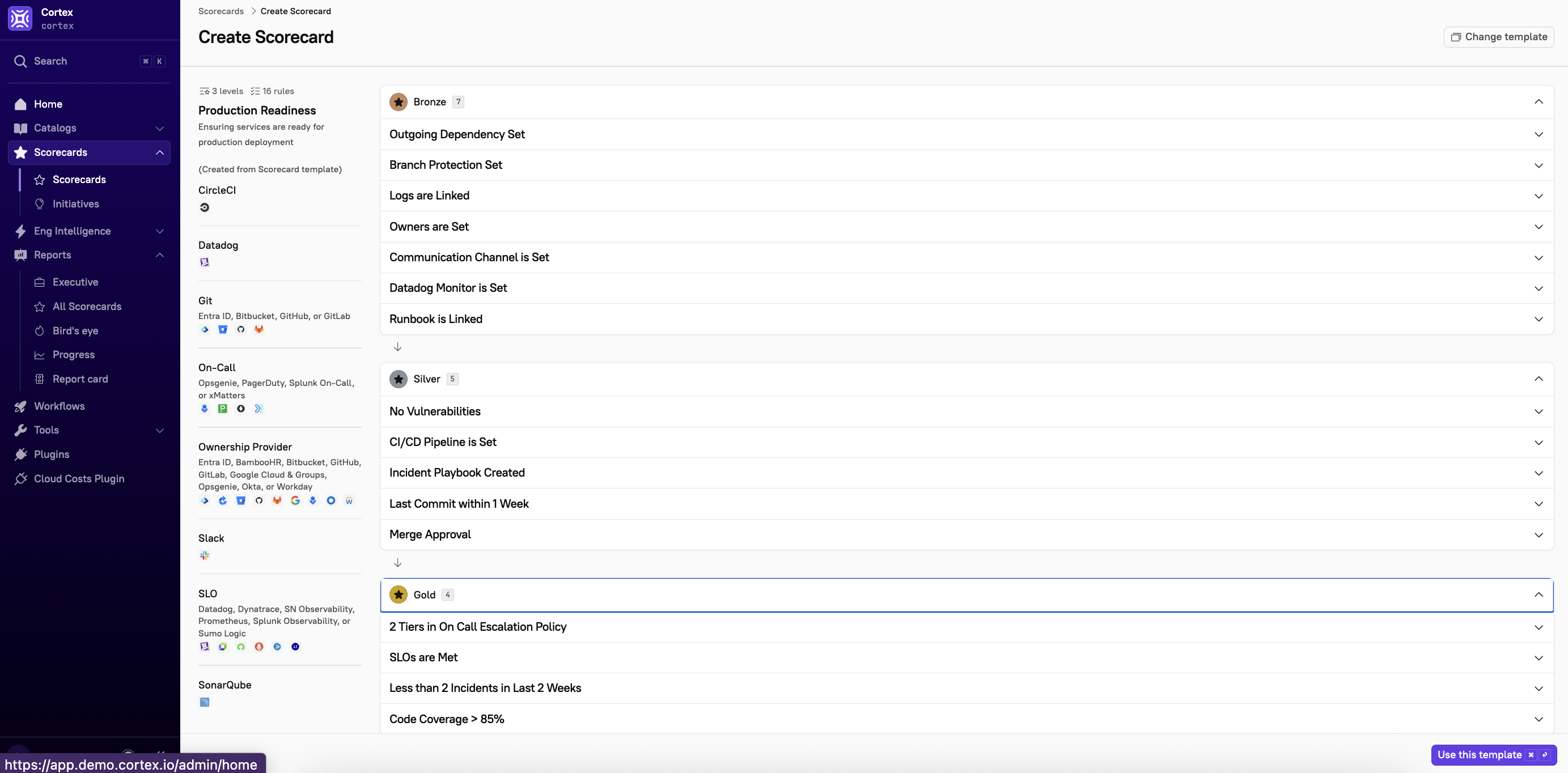
This template is structured into three levels: bronze, silver, and gold, each representing increasing levels of production readiness.
 Let's take a look at a few key rules from the template Scorecard.
Let's take a look at a few key rules from the template Scorecard.
Bronze
Bronze rules ensure that basic production readiness standards are in place, helping teams establish key operational and development best practices. Rules can include factors like ensuring that an owning team is responsible for this entity or confirming the associated repository uses branch protection.
Outgoing Dependency set: This service has at least one outgoing dependency defined in Cortex.
Branch Protection set: The default branch is protected.
Logs are Linked: This service has a link to its logs.
Owners are Set: This service has ownership represented in Cortex.
Communication Channel is Set: This service has a linked Slack channel.
Datadog Monitor is Set: Service has an associated Datadog monitor.
Runbook is Linked: This service has a linked runbook.
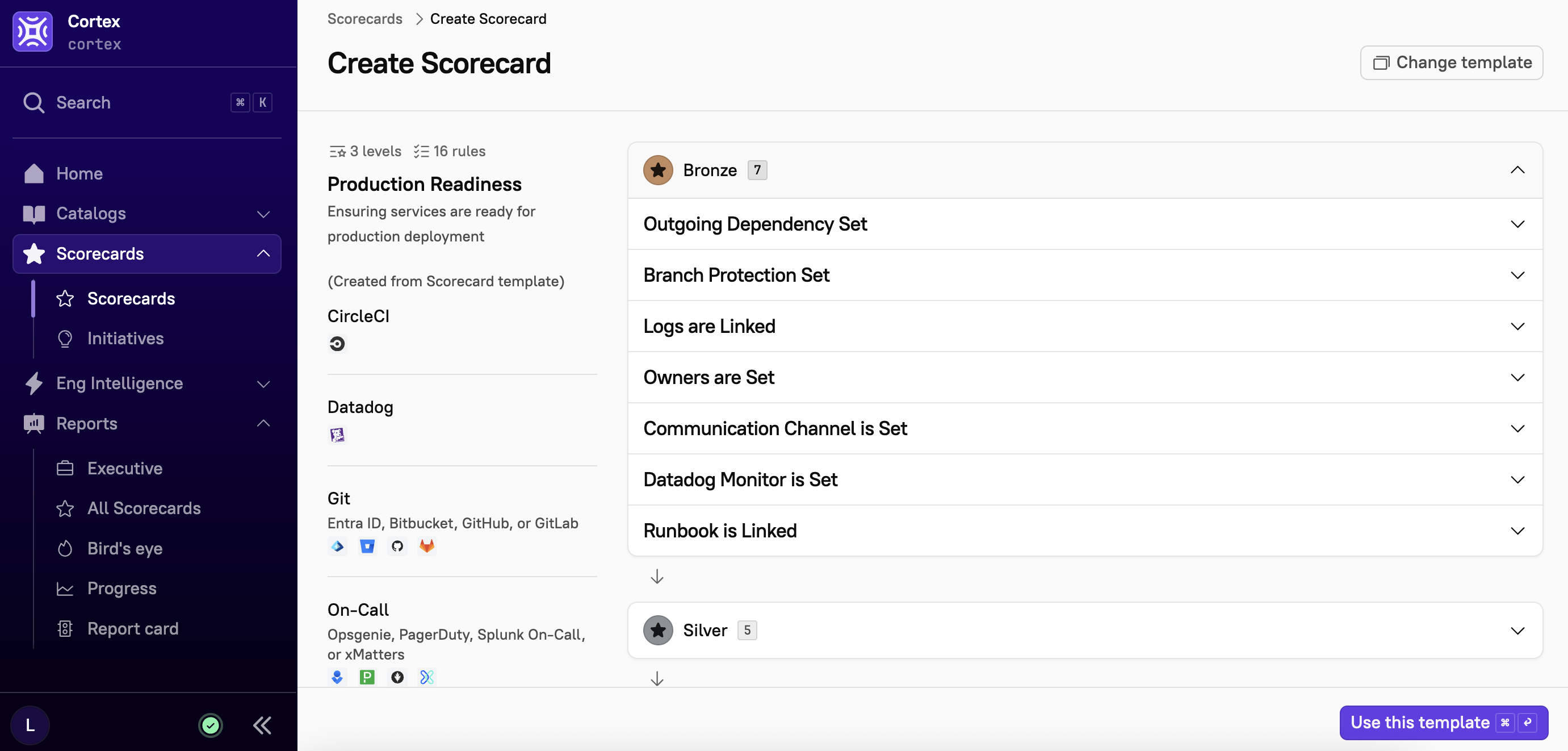
Silver
Silver rules introduce more rigorous quality and operational checks helping teams enhance service resilience and maintainability, like the number of vulnerabilities, or confirming the CI/CD pipeline is in place for automated deployments.
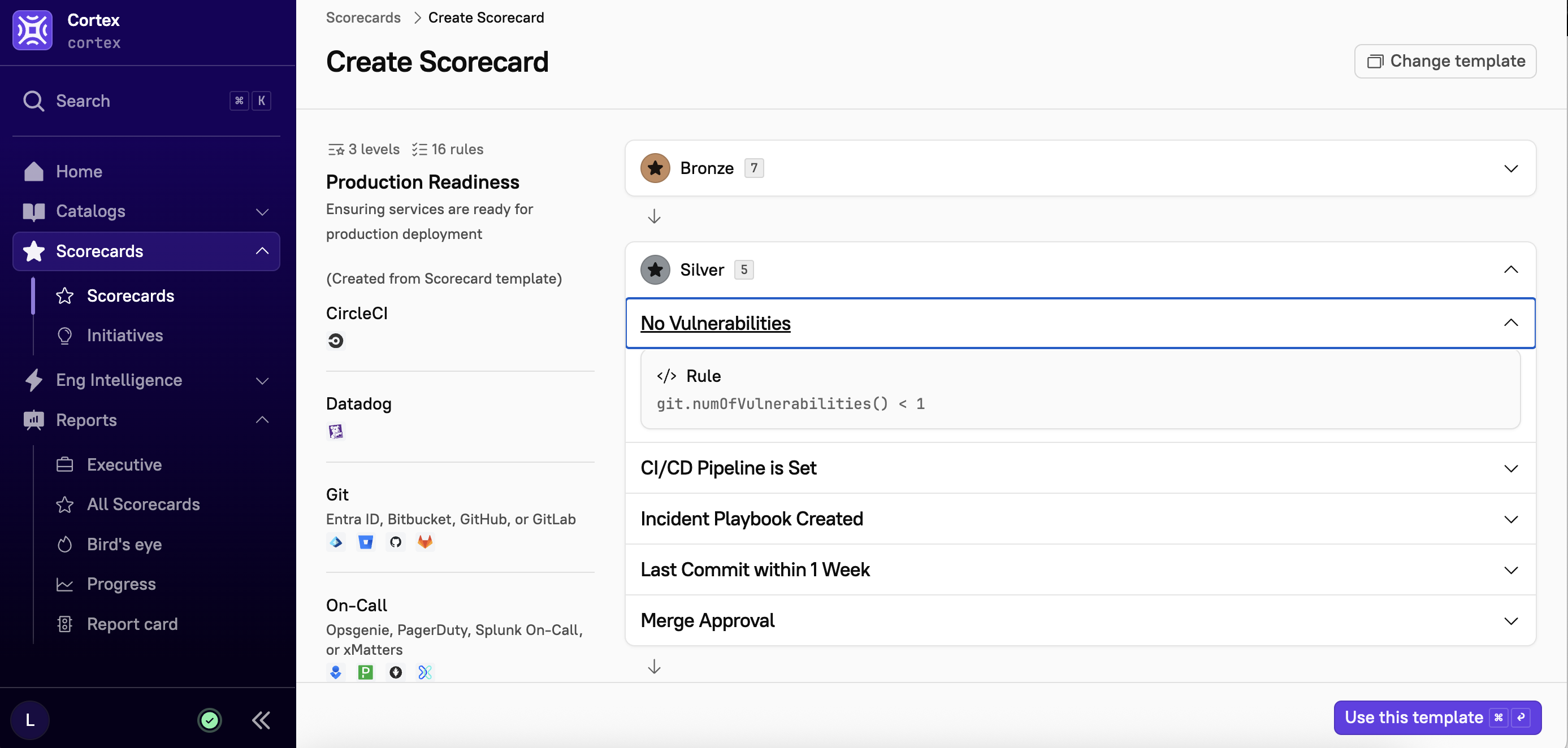
No Vulnerabilities
CI/CD Pipeline is Set: If CircleCI integration is used for this service, a pipeline is set. If not, a gitlab-ci.yml file is present in the associated Git repository.
Incident Playbook Created: This service has an incident playbook created, linked in their Runbook. This value originates from custom data key incident-process-documented.
Last Commit: The latest commit is a week or less old.
Merge Approval: At least one approval is required to merge.
Gold
Gold rules represent the highest level of production readiness, ensuring security, monitoring, and operational excellence. These can include monitoring code coverage or the number of incidents.
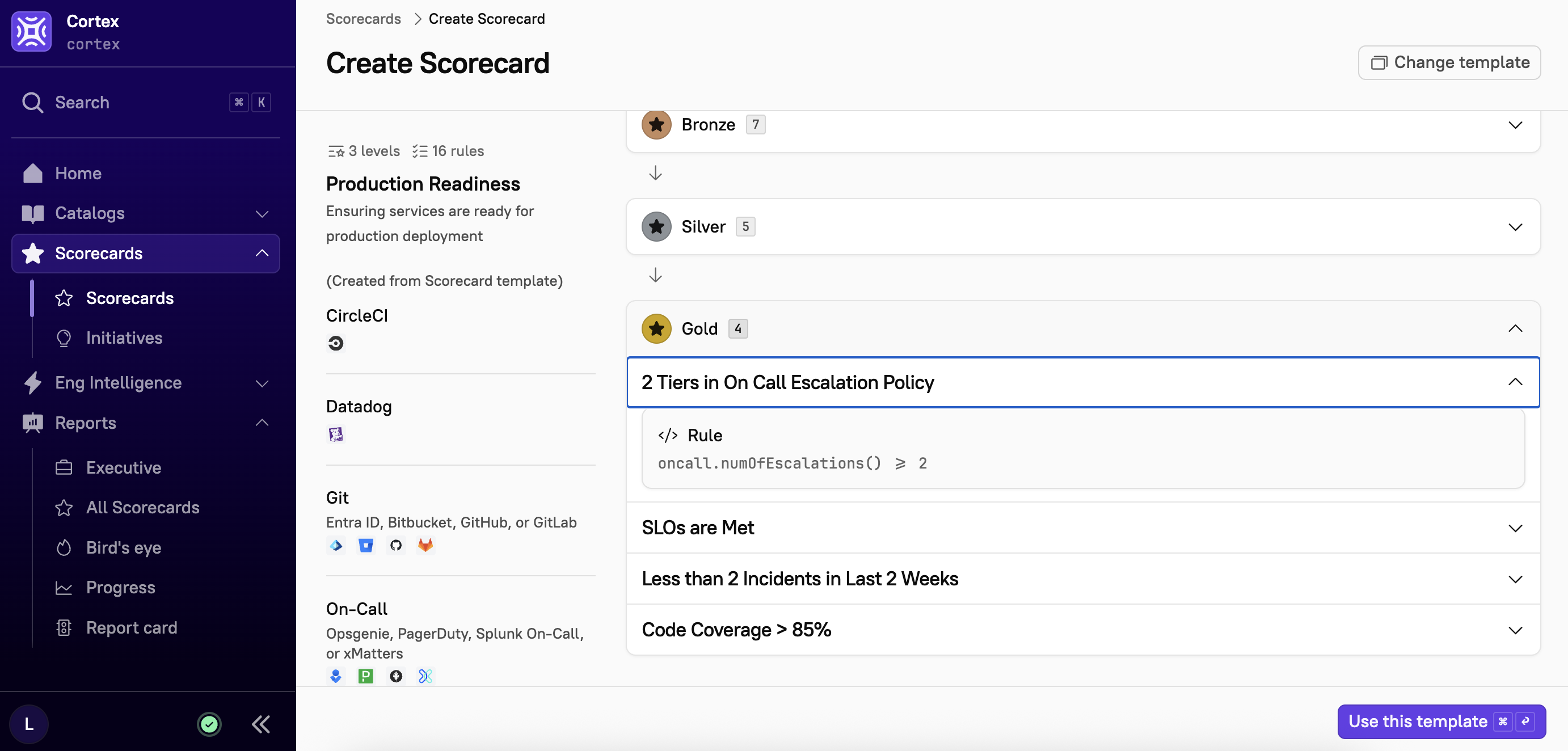
2 Tiers in On Call Escalation Policy: Check that there are at least 2 levels in the escalation policy, so that if the first on-call does not act, there is a backup.
SLOs are Met: Service is passing all SLOs.
Less than 2 Incidents in the Last 2 Weeks: Service has had 0 or 1 incidents within the last 2 weeks.
Code Coverage > 85%
If a rule is valuable to your organization, keep it at its assigned level or move it to a higher level to emphasize its importance. You can even adjust the rule’s point value to indicate its weight.
If a rule is not relevant, remove it.
And if your organization has additional production readiness requirements not covered by the template, add new rules to capture them.
Get the template
Cortex customers can visit Cortex and make a copy of the Production Readiness template Scorecard to get started.
If you’re not already a Cortex customer, request the customizable template today.
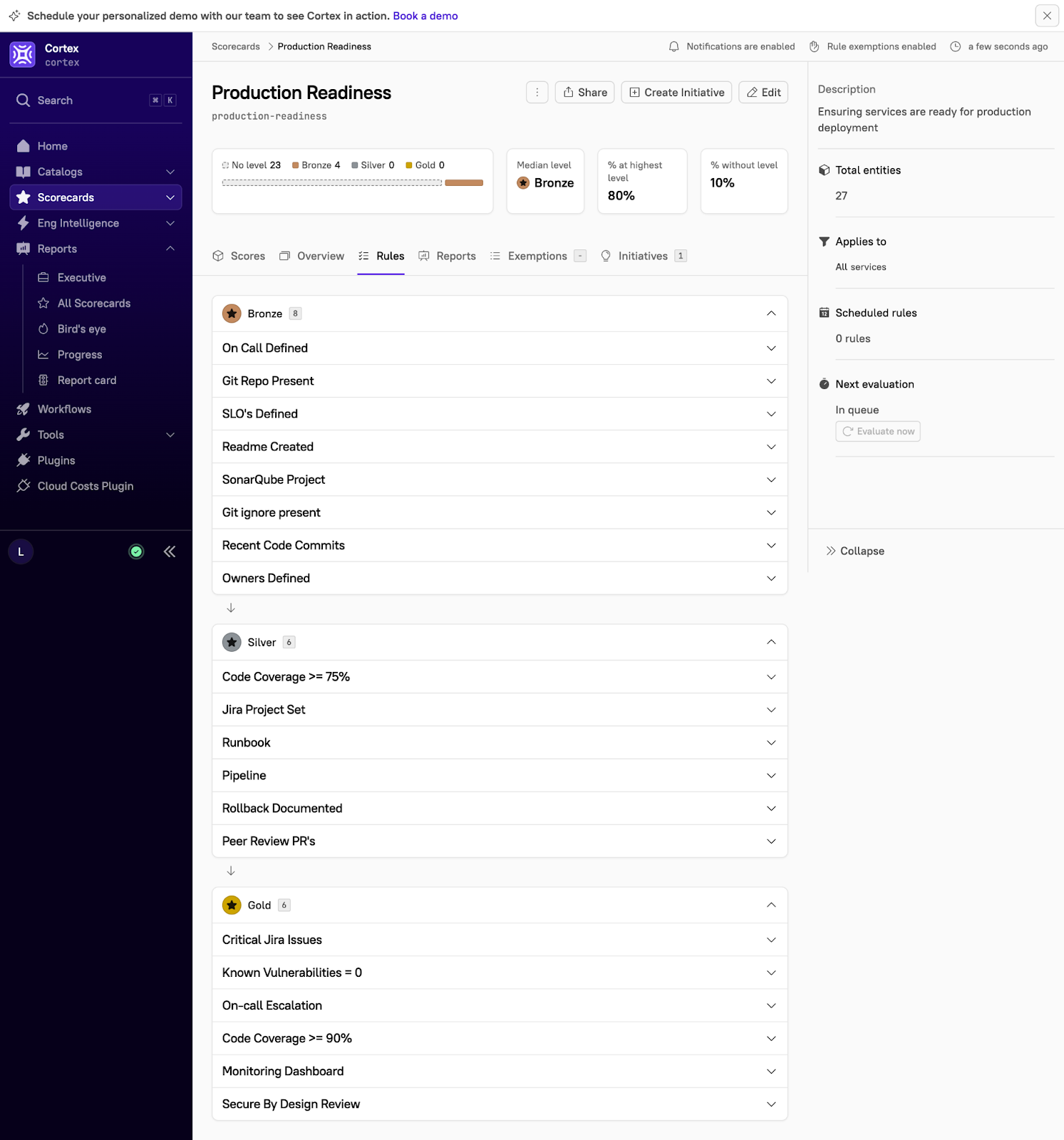 Here’s another example of a Production Readiness Scorecard. Beyond the rules listed above, this example includes a “Secure by Design Review,” a rollback documented, and no outstanding PRs.
Here’s another example of a Production Readiness Scorecard. Beyond the rules listed above, this example includes a “Secure by Design Review,” a rollback documented, and no outstanding PRs.
Reporting & improving
Once your Production Readiness Scorecard is in place, the Bird’s eye report provides deep insights into how entities are performing by visualizing Scorecard data as a heat map.
This report is designed to be hierarchy-aware, making it easy to navigate the data.
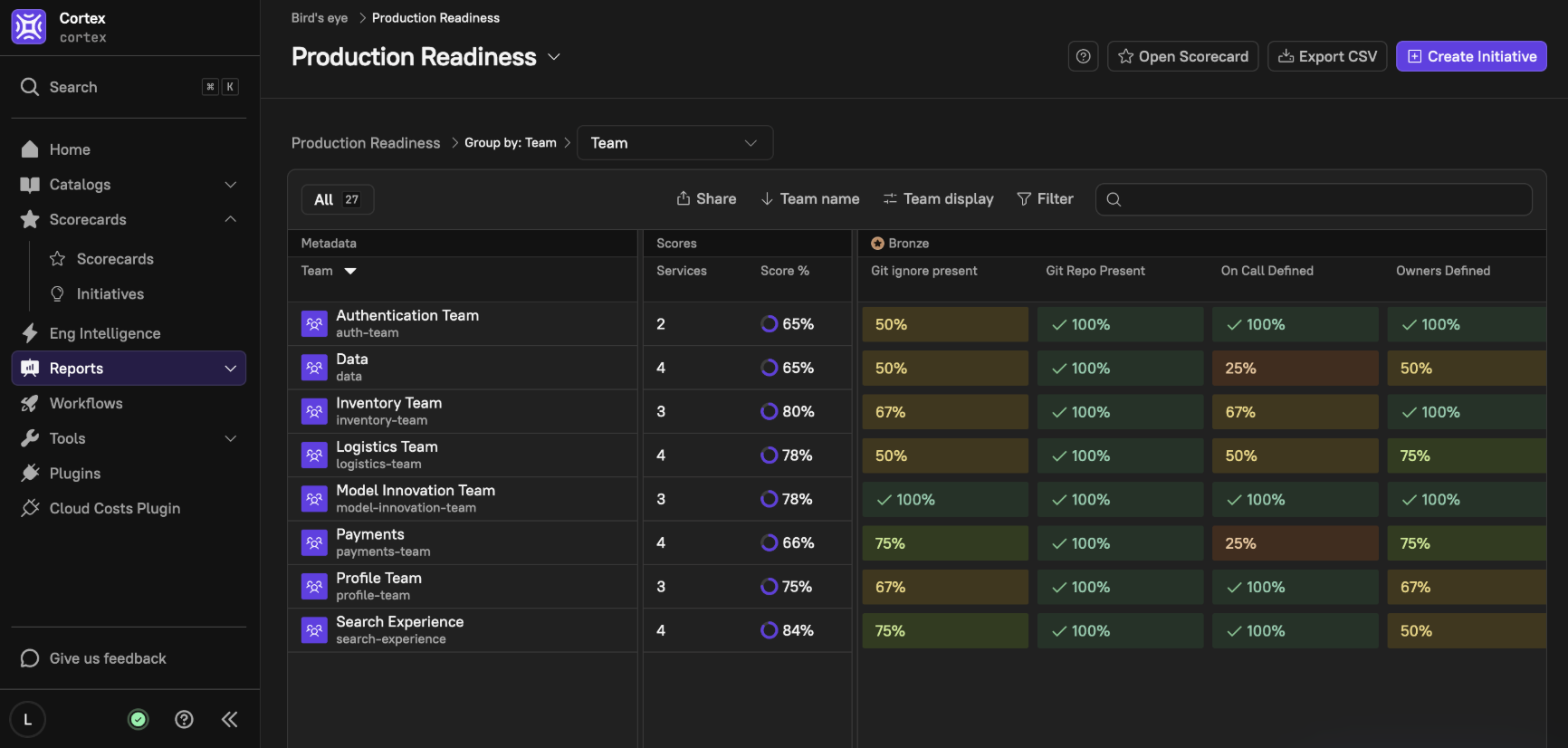
With the Bird’s Eye Report, leadership can compare how well the services align with each rule we created. Filter by component, teams, domains, or groups.
Tracing left to right tells us the average score for each rule, making it easy to see where teams need a little more help.
In this example, the Data team struggles most with ensuring SLOs are met for software they own.
And, if we want to accelerate how quickly the team addresses this gap, we can create an "Initiative" for this team, or all others.
While Scorecards will show you progress over time, Initiatives can help you coordinate your team members, prioritize tasks, and ensure that everyone is adhering to the same standards and meeting deadlines. Initiatives offer a streamlined view into the most critical tasks, improving not just the efficiency of your team members, but the accountability of your teams as well.
Initiatives allow you to prioritize specific rules within a Scorecard and set deadlines for higher priority tasks. Cortex will notify owners and team members when deadlines are approaching, so once you set up an Initiative, everything else is handled for you.
For example, your Production Readiness Scorecard may have a rule that measures whether each service has an on-call rotation configured through PagerDuty. To make sure that all services actually have active on-call rotations within 30 days, you could create an Initiative with a due date in 30 days, which will notify entity owners if they need to take action on their entities.
Deeper Dive: Building your Production Readiness Scorecard
Achieving consistent and enforceable production readiness requires clear standards and automated tracking. With Cortex Scorecards, organizations can define, measure, and enforce their Production Readiness Standards across all services.
Cortex Scorecards leverage rich metadata reporting. The more metadata available, the more actionable and insightful your Scorecards become. Metadata provides the necessary context for assessing compliance, automating checks, and ensuring teams are meeting organizational standards.
Cortex integrates with various tools and platforms to ensure a comprehensive view of production readiness. Key categories include:
Ownership – Ensures clear accountability by linking services to the appropriate teams
On-Call – Tracks on-call responsibilities to confirm that support teams are always assigned
Git – Enforces best practices like peer reviews, CI/CD pipelines, and versioning
SLO (Service Level Objectives) – Monitors system performance against defined reliability targets
Cortex Entity Metadata – Built-in data to enrich entities like links, tags, and documentation
Custom Data – Define and track custom metrics unique to your operational needs
Ownership
Ownership is a critical pillar of Production Readiness, ensuring that every component of your software architecture has clear accountability. In Cortex, teams function as both entities and owners of other entities, such as services, infrastructure, and operational components.
To maintain service reliability and operational efficiency, organizations must establish well-defined ownership structures. This helps drive accountability and ensures that all services are properly maintained. Cortex simplifies this process by automatically synchronizing teams and members from various identity providers, eliminating manual tracking and ensuring up-to-date ownership records.
Supported identity providers
Cortex seamlessly integrates with multiple identity providers, allowing organizations to keep ownership data accurate and aligned with team structures. Supported providers include:
AzureDevOps
BambooHR
Entra ID (formerly Azure Active Directory)
GitHub
GitLab
Google
Okta
Opsgenie
ServiceNow
Workday
Cortex syncs teams and their members daily at 6 AM UTC, ensuring that the latest ownership data is always available. Below is an example of a team entity's details page in Cortex, showing their owned catalog entities:
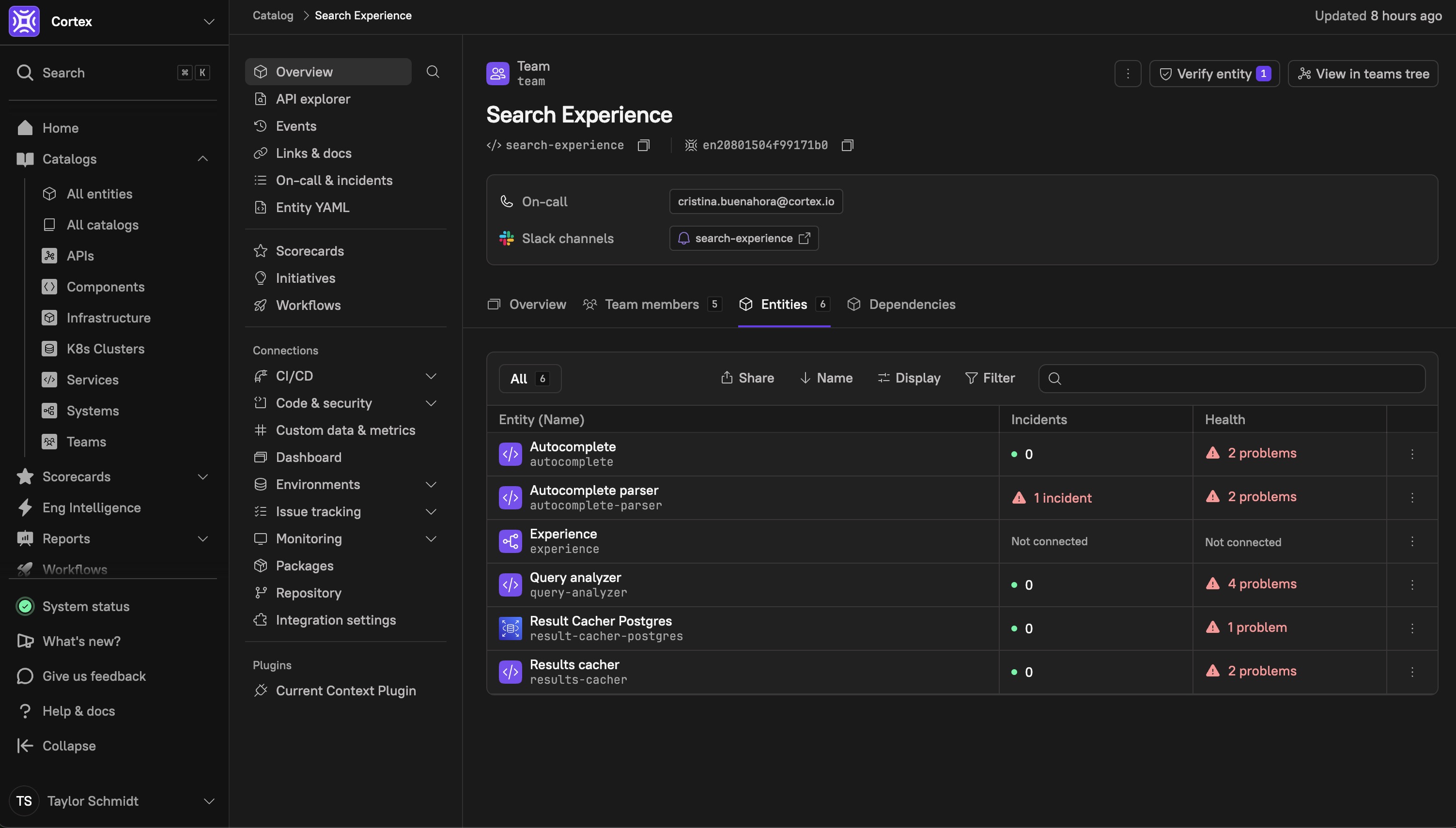
And, Cortex automatically predicts ownership, based on real contribution data, and mapped to live team structures from systems like Okta and GitHub.
HR-to-Git Mapping: Cortex connects the dots between identity systems and source control handles (e.g., matching GitHub usernames to corporate emails).
Automatic Team Updates: When people move teams in your org, Cortex reflects that instantly, ensuring ownership data stays current without manual cleanup.
Bulk Ownership Suggestions: Cortex predicts team ownership across hundreds or thousands of repos. Validate or override with just a few clicks.
Verification Workflow: Teams can explicitly confirm ownership for audits, SOC 2, ISO compliance, etc.
By leveraging ownership enforcement in Cortex Scorecards, you can ensure that every service and infrastructure component has a designated team responsible for its maintenance, compliance, and operational health. This not only enhances visibility across engineering teams but also prevents orphaned services that lack accountability.
By integrating with identity providers and automating ownership synchronization, Cortex enables teams to track, verify, and enforce ownership structures with minimal manual effort. Establishing clear ownership as a core production readiness standard leads to more reliable, scalable, and well-maintained software systems, reinforcing a culture of accountability and operational excellence.
On-call
A key aspect of production readiness is ensuring that every service has a dedicated on-call team available to respond to incidents in real time. Without a structured on-call system, issues can go unaddressed, leading to downtime, service degradation, and operational risks.
Cortex integrates with industry-leading on-call management platforms, allowing organizations to track, enforce, and verify on-call readiness for their services.
Supported on-call integrations include:
Opsgenie
PagerDuty
Rootly
Splunk On-Call (VictorOps)
xMatters
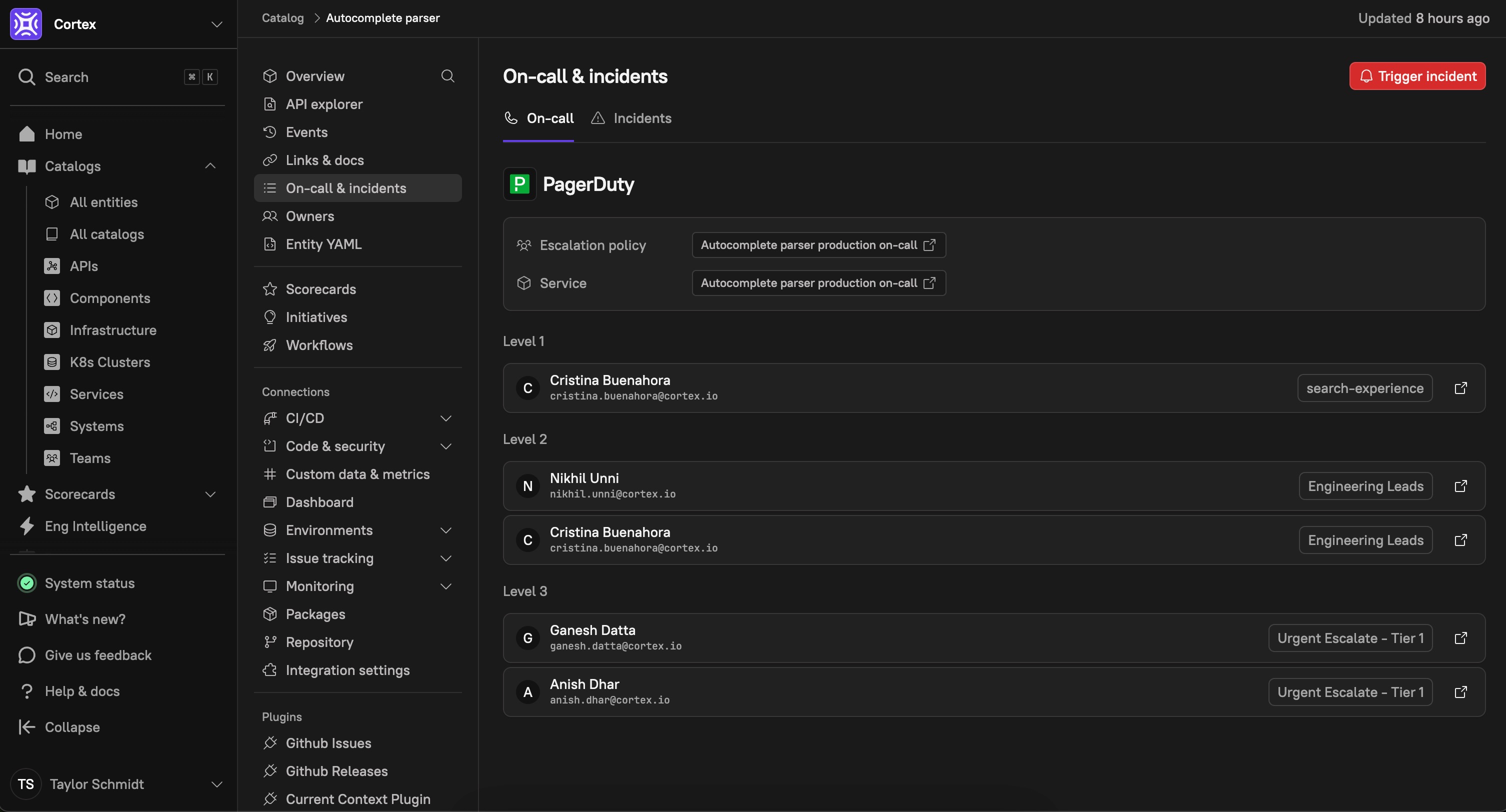
By linking on-call schedules, escalation policies, and service associations within Cortex, teams can ensure there is always a responsible contact available to resolve incidents efficiently. Scorecards can be used to enforce on-call readiness checks, such as verifying that escalation policies are in place and ensuring that all critical services have an active on-call rotation. This proactive approach minimizes response delays and strengthens incident management workflows across the organization.
Version control
Adhering to best development practices is essential for maintaining production readiness and ensuring that code is reviewed, tested, and deployed with consistency. Cortex integrates with Git providers to bring version control metadata into Scorecards, enabling teams to automate compliance checks and enforce coding standards.
Supported version control providers include:
GitHub
GitLab
Azure DevOps
Bitbucket
With version control integrations, Cortex Scorecards can verify key development practices, including:
Peer-reviewed pull requests to ensure code quality and prevent unverified changes
CI/CD pipeline enforcement to confirm that automated build and deployment processes are in place
Proper versioning to track releases and maintain consistency across environments
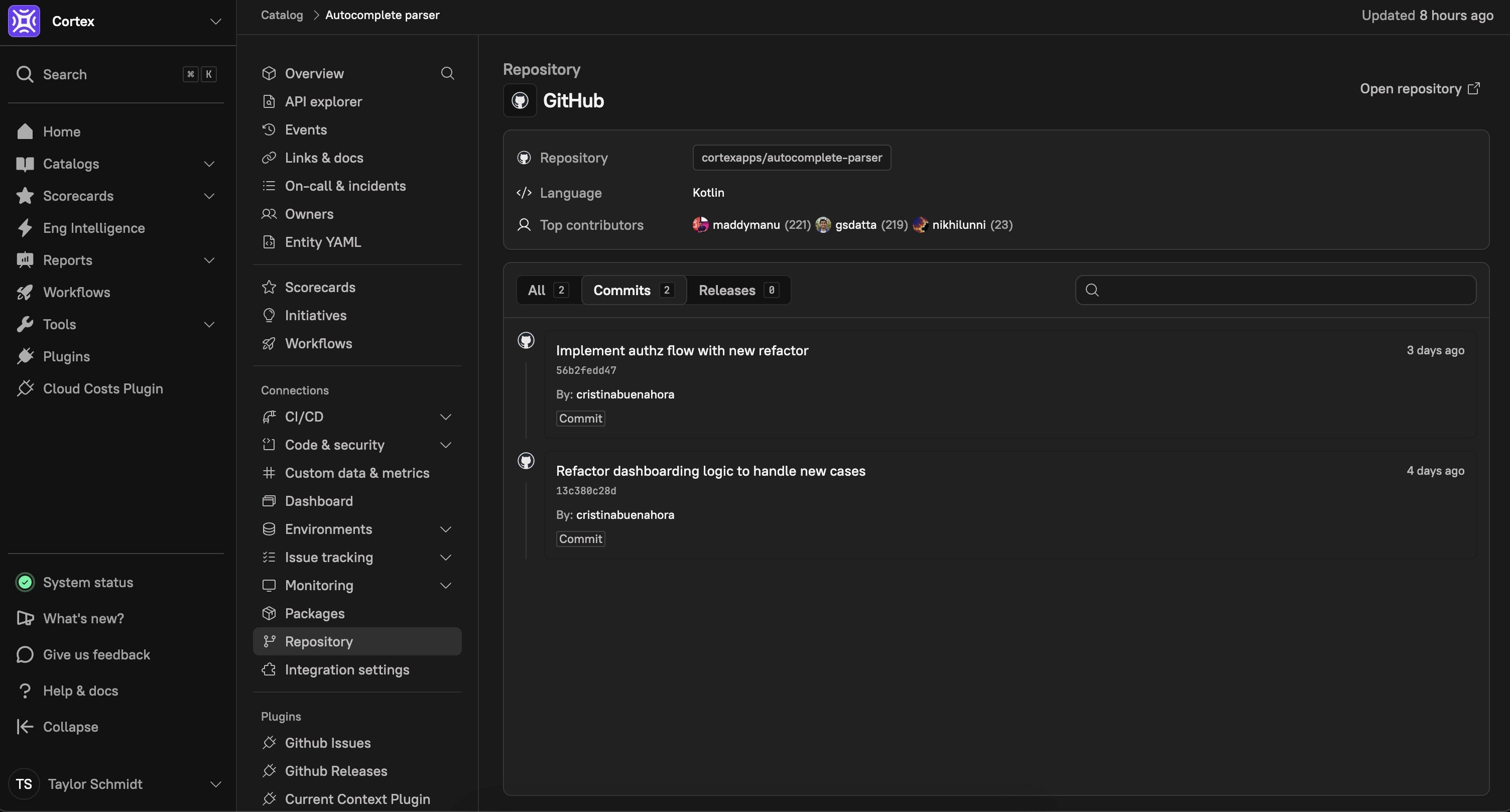
By leveraging Git metadata within Cortex, organizations can identify gaps, standardize development workflows, and ensure deployment readiness before software reaches production. Automating these checks not only enhances code quality and security but also streamlines engineering efficiency and compliance.
SLOs
Reliability is a core pillar of production readiness, and Service Level Objectives (SLOs) provide a measurable way to ensure that services meet performance and availability targets. Cortex integrates with leading observability and monitoring platforms to track and validate SLO compliance, helping teams proactively manage reliability and enforce operational standards.
Supported SLO integrations include:
Datadog
Dynatrace
Lightstep
Prometheus
Splunk Observability Cloud (SignalFx)
Sumo Logic
By incorporating SLO tracking into Cortex Scorecards, organizations can:
Define and enforce reliability targets, ensuring that services meet agreed-upon performance thresholds.
Ensure critical monitors are in place to detect and respond to service performance degradations before they impact users, leveraging Cortex Scorecards to verify monitoring coverage
Validate compliance with operational goals, ensuring that key services align with business expectations for uptime and availability.
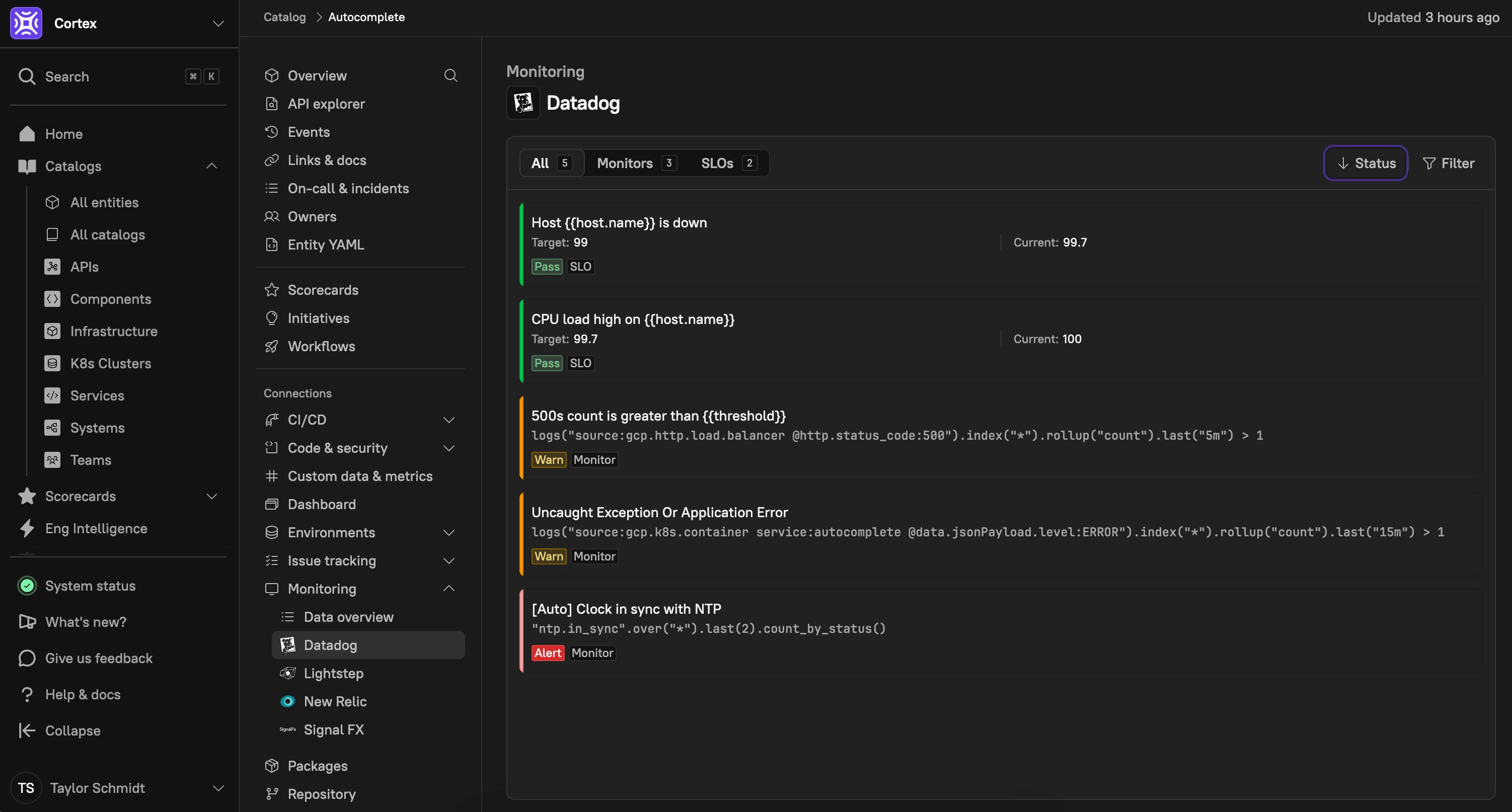
With SLO integrations in Cortex, teams can automate production readiness checks, enforce data-driven reliability standards, and ensure consistent performance across critical services.
Unique readiness rules
Cortex provides built-in metadata capabilities that enrich Scorecards, enabling teams to track service health, compliance, and operational standards with greater accuracy. In addition to built-in metadata, custom data fields allow organizations to tailor production readiness assessments to their unique requirements.
Key metadata capabilities in Cortex include:
Built-in links to associate entities with essential documentation, such as logs, runbooks, dashboards, and incident reports.
Cortex-native metadata tracking, including ownership, on-call status, dependencies, and integrations, to ensure all services meet predefined standards.
Custom data fields to capture additional compliance, security, or operational metrics unique to an organization’s workflows.
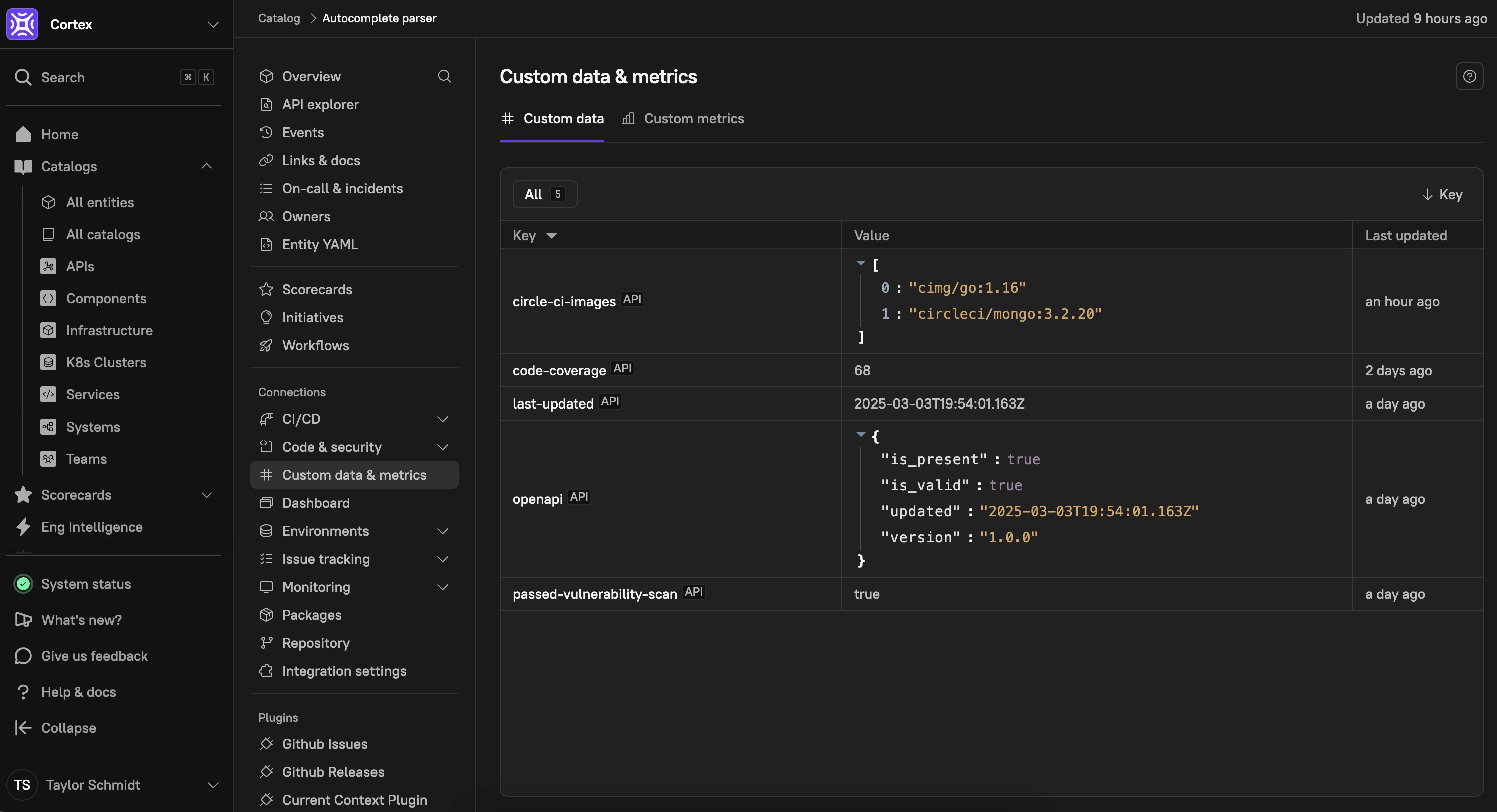
By leveraging both Cortex-built-in metadata and custom data, teams can create robust, adaptable Production Readiness Scorecards that provide a comprehensive, real-time view of service reliability. These features enable organizations to enforce best practices, improve accountability, and ensure alignment with evolving business and regulatory requirements.
Best practice tips for managing production readiness
Production readiness now needs to be as dynamic as the software being evaluated. It’s no longer good enough to ensure bugs and vulnerabilities have been addressed before initial deployment; teams need to ensure continuous connection to code coverage vulnerability scanners, while enforcing some standard of resolution time.
Some production readiness frameworks are hundreds of lines long, but with the right integrations, automations, and continuous monitoring, even something of this size can be incredibly effective without being equally burdensome to developers.
Here are some best practice tips to embed a sustainable, scalable production readiness culture:
Ensure clear ownership and accountability
This is often the most challenging yet critical first step. Every service, application, and resource must have a designated owner. Without clear ownership, it's impossible to drive action on readiness gaps.
Shift to continuous readiness, not one-time reviews
Production readiness is not a "set it and forget it" activity. Code changes, dependencies evolve, and new vulnerabilities are discovered daily. You need a framework for continuous evaluation.
Centralize and standardize your readiness criteria
While different types of software may have nuanced requirements, a core set of standards should apply broadly. These standards must be centrally located, well-documented, and consistently applied.
[Image: Cortex Scorecard dashboard screenshot. Caption: Cortex Scorecards provide a centralized, real-time view of service readiness against defined standards. Alt text: Screenshot of Cortex Scorecard dashboard showing various services and their compliance levels for production readiness criteria.]
Bias toward automation wherever possible
Manual checks are time-consuming, error-prone, and don't scale. Automate the collection of readiness data, the validation of standards, and the notification of deviations.
Measure production readiness like you measure performance
Treat readiness as a key metric. Track it, report on it, and set goals for improvement. Make readiness scores visible to teams and leadership to drive awareness and incentivize progress.
Promote a culture of cross-functional collaboration
Production readiness is a shared responsibility. Foster a culture where development, operations, SRE, and security teams work together towards common readiness goals. Open communication and shared objectives are key.
Always production-ready
If production readiness still feels manual or unreliable, it’s time for a better system. The best teams don’t wait for incidents to reveal gaps. They build always-on systems that surface problems early, standardize expectations, and create a shared culture of accountability across engineering.
This guide has outlined what production readiness really means today, the common pitfalls to avoid, and how teams across your organization can benefit from moving to a continuous model. The next step? Make it real.
Get the template to build your own Production Readiness Scorecard.
Whether you're just starting out or looking to improve your current approach, the Cortex Scorecard template gives you a proven structure to work from—with customizable rules that reflect your team’s maturity, tools, and standards.
Cortex customers: Visit the Cortex app to explore and clone the Production Readiness Scorecard template.
New to Cortex? Request access to the template in your own sandbox environment and start building your own Production Readiness Scorecard today.
Your services should always be ready. Now you can make sure they are.


