
After decades as a software engineer, I’ve seen firsthand how complexity can grow exponentially with scale. Thankfully, over that time, quite a few tools have come along to help manage some of that complexity. One great example is the Internal Developer Portals (IDPs), which were built to connect an engineering organization’s architecture, processes, documentation, and definitions and alignment to standards of health.
IDPs definitely help shore up complexity to drive alignment—but what happens when an organization already has pretty robust processes, and a pretty clear view of what their information architecture should look like? Do they... try and jam their model into the framework of some off-the-shelf IDP, or do they take on the enormous project of building their own from scratch? Neither! If Cortex is in the picture ;)
In this blog I’ll shed some light on how Cortex’s catalogs can be customized for the workflows that matter most to your business, using our own internal use case of centralizing project management as an example.
The challenge at Cortex
I’ve had the chance to see some major shifts in tech throughout my career: from on-premises compute to the cloud, monoliths to distributed microservices architectures, and more. These experiences also came with a fair bit of exposure to the business problems and tools that sit adjacent to engineering—giving me a slightly broader perspective. So when I first saw Cortex, the technical and business value was obvious—mitigate the downsides of complex architecture and deployments, while enabling teams and organizations to retain all the upside of growth. To explain what we do to others outside this market, I found myself using analogies to project management tools—'but IDPs kick it up a notch—since they have all the data you need to not only track project status but drive action against tasks," I would add. Given this added context, it's probably not a surprise that I eventually found myself wondering, 'Could we model a project using Cortex?'
Many qualities the team cared about when running a project were similar to those of the services, resources, or domains already tracked in Cortex (i.e., owners, last updated, dependencies, Slack channel, etc). It was promising, but to put the idea into practice, we first had to decide how we wanted to represent projects. Only then could I put the platform to the test, to see if it was flexible enough to accommodate our desired information architecture.
Defining project architecture in Cortex
Defining information architecture for projects starts with thinking about what things we actually care about tracking for a project at Cortex. There are quite a few: for starters, project metadata, such as project owners, dedicated Slack channels, documentation location or links, project status, target completion date, etc. The next, similar to metadata, was health. For projects, this meant that they had the right complement of metadata, and that all (or most) of the fields had meaningful values (i.e., the owners field is not blank). Building off the project health was an alerting or reporting requirement: if a project is unhealthy, someone (i.e., those owners we keep talking about) would need to be alerted.
Beyond metadata contained wholly within the project, we also cared about modeling hierarchical and dependency relationships of projects with one another. The simplest hierarchical relationship was whether a project was active, completed, or upcoming. This hierarchy needed to be further nested within a hierarchy of teams (i.e., the engineering team). And across these hierarchies, it needed to be easy to move projects between buckets, for example, moving a project from active to completed. And perhaps most importantly, the whole system needed to be easy to keep up to date, with minimal effort or interaction.
Implementing a unique information architecture
After sketching it all out, it was time to try to put rubber to the proverbial road: how would we actually represent this information architecture in Cortex? Taking advantage of Cortex’s catalog customization, I decided that the best approach would be to use a new project entity alongside hierarchically nested catalogs.
Catalog customization, simply put, enables a higher level of abstraction and customization on core Cortex concepts. The Cortex platform is opinionated, with four pre-defined and distinct entities that engineering teams often need to track: domains, resources, services, and teams. These entities could be put into catalogs (think: folders) and nested in whatever hierarchy an organization wanted. Catalog customization extends the opinionated structure: the four suggested entities continue to exist, but teams using Cortex can also define arbitrary entities and include flexible metadata within them.
Taking advantage of catalog customization, we were able to accomplish the goal of modeling projects in Cortex in just three steps:
1. We created catalogs for active, paused, completed, and upcoming engineering projects.
2. We defined a metadata structure for a “project” entity that contains documentation links, owners, project slack channel, and other key data.
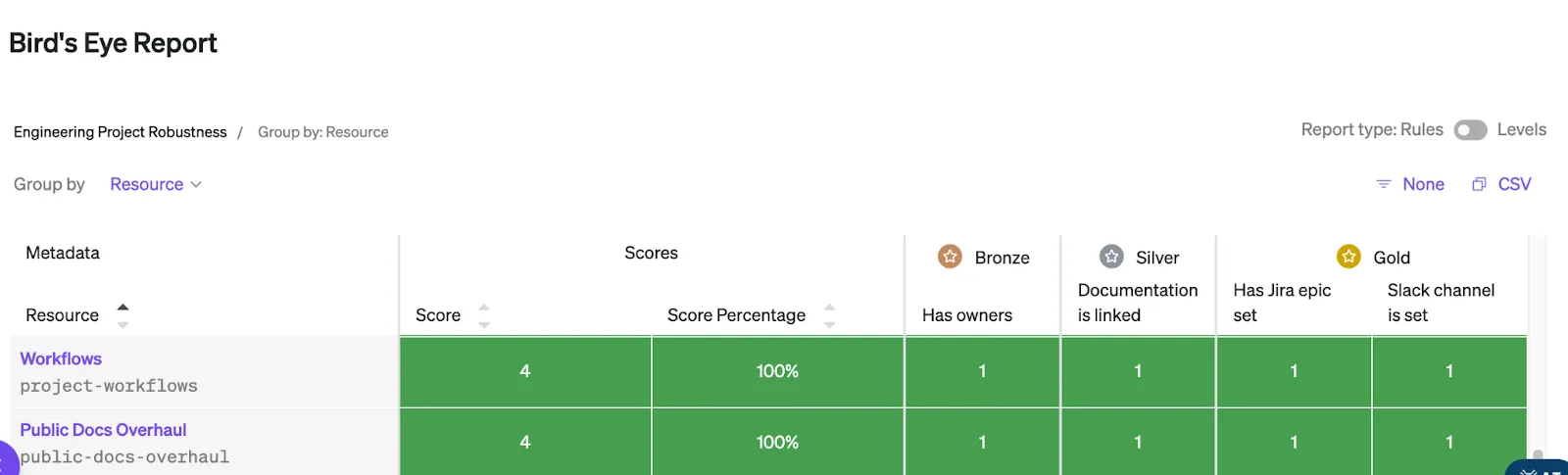
3. We defined some scorecard criteria for project health. These criteria account for projects having owners, linked documentation, and a slack channel specified.

Benefits of tracking projects in Cortex
While the setup process was relatively simple, thanks to catalog customization, the benefits we saw were significant.
Tool consolidation
First and foremost, tracking projects in Cortex meant that we had one fewer tool in our workflow. Since we were already used to using Cortex to track software services, domains, and more, the new use case felt like a natural extension. It also meant that we had one fewer tool to learn about, maintain, or go to when seeking information. Unifying the two use cases in a single tool also meant that there was a more unified source of truth for project and service information, and less worrying about whether the right Google Drive folder or Notion page was shared with the right people. Or even worse—that it was, but people didn’t know about it.
Platform extensibility
The second broad bucket of benefits came from the flexibility and extensibility of the platform. The prior was clearest in scorecards, which enabled a quick “bird’s eye view” of project health in a way that was uniquely defined to be meaningful for projects at Cortex and harder to find with other tools. But when we demonstrated the project-tracking use case to the company at large, it was the extensibility of the platform, coupled with project tracking, that garnered the most excitement.
Risk reduction
The promise of using integrations, like Cortex’s existing GitHub integration, to bring live data into tracked project entities, was significant. Tedious workflows, like seeing the list of projects affected by a vulnerability, such as log4j, could be done at a moment’s notice. Teams throughout Cortex are optimistic that using live integration data in this way could bring significant improvements to the speed and thoroughness dealing with reliability and security issues on projects. And that’s just the tip of the iceberg, given the integrations to the Cortex platform that continue to be released.
Wrapping up
While complexity may grow with scale, the right tools can help an organization rein it in. This was the case at Cortex internally, where I got the chance to revamp project tracking, letting internal teams understand health and status at a glance, with minimal maintenance work. I also got to see the importance of adaptability in software tools, particularly in an enterprise environment, where organizations are often opinionated and need tools that can conform to, rather than chafe at, those opinions. The right software, as we saw, can and should evolve with its users. Whether your organization is seeking an opinionated approach to managing your services and projects, or you’re more interested in seeing how Cortex can mold itself to your enterprise use case, please reach out to schedule a live demo.


