
Today's Recipe: Getting your Skeletons into Cortex: A tale of two solutions
Time: 1-10 hours
Difficulty: Easy or challenging
Serves: API key owners
What We're Cooking
In this recipe, we’ll explore two different ways to track ownership for your Cortex API keys.
Ingredients
1 or more skeletons in the closet (API keys without owners, names, or descriptions)
A dash of the Cortex Command Line Interface
A heavy dose of over-engineering reflections
A dash of shell scripting knowledge
Optional: 1 GitHub account with ability to run Actions
Optional: A dash of GitHub Actions knowledge
Preparation Steps
Step 1: Identify the business problem you are trying to solve
At Cortex, I want to ensure we are drinking our own champagne, using our own product to drive value and improve engineering processes.
I recently reviewed our API keys in our production instance of Cortex and found some really spooky data:
60 keys, 53 of which were active
47 of the 53 keys had Admin rights
Almost none of the keys had an expiration date set
A quick review found that a vast majority of the keys had never been used, so they were deleted. That left 9 active keys.
However, there was this skeleton in the closet that was the catalyst for this recipe:
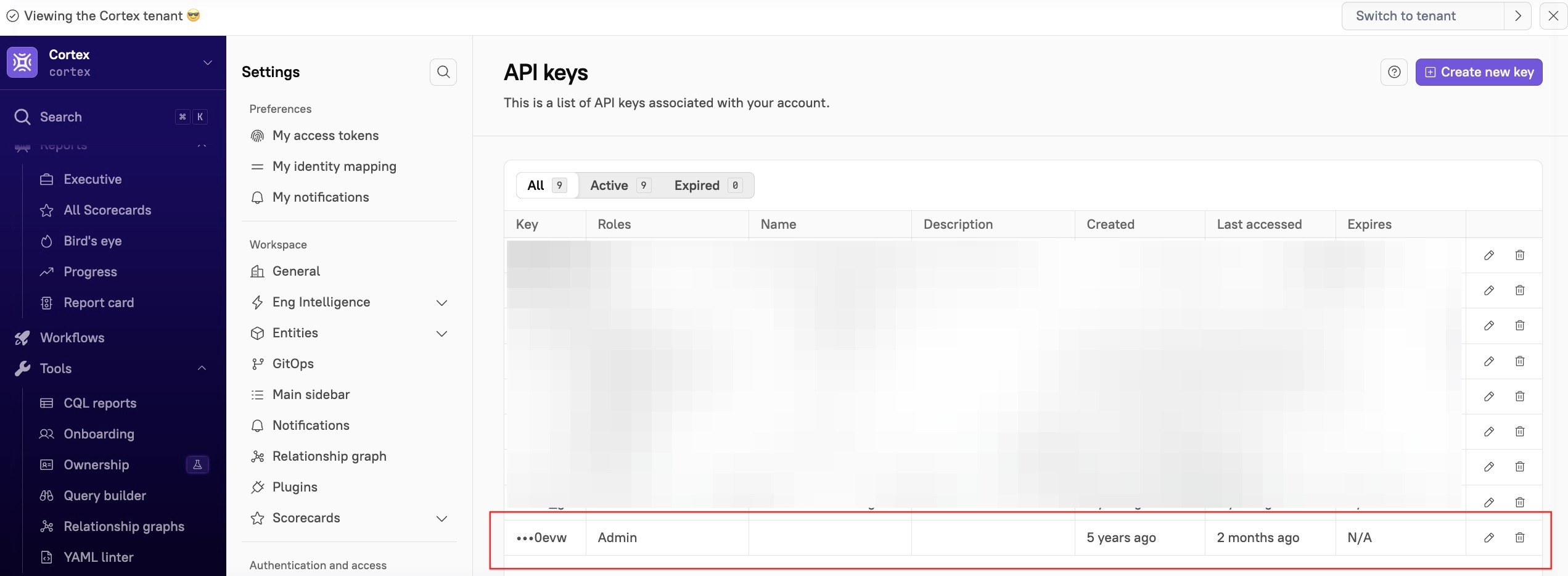
A five-year-old key that doesn’t appear to be used frequently, but has been used in the last two months.
We’ve all heard horror stories of unknown infrastructure that runs smoothly for years only to encounter a hiccup at the least opportune time.
Not on my watch! It was time to roll up the sleeves and investigate this skeleton and the other keys.
The business problem I am trying to solve is: I don’t know who owns the API keys in our production Cortex instance and I don’t know how they are being used.
Like a good Halloween movie plot, there was more than one evil force to deal with. In addition to the rogue API key, there was a rogue solution architect: I over-engineered the original solution, hence the tagline of this recipe about multiple solutions.
This recipe is a solution but also a cautionary tale.
Step 2: Thinking through the design of the solution
When we talk to customers about shipping reliable software we position it with three key actions: understand your data, unlock insights and drive action.
I understand the data I’m working with - it’s API keys. What I don’t understand is who is using them and how.
It seemed natural to me to create a custom entity in Cortex to track these API keys. Unlocking insights would be done with a Scorecard that tracked the attributes that I needed. Action would be driven with Cortex Workflows which would allow API keys to be created, deleted and rotated.
I felt really good about this thought process, but I realized that I got off track right out of the gate. My stated business problem was that I didn’t know who owned the keys or how they were being used. Nowhere in my stated business problem did I mention the need to create or rotate the keys.
Ironically, I violated the primary tenet that is most important to me:

The design I landed did not live up to this principle:
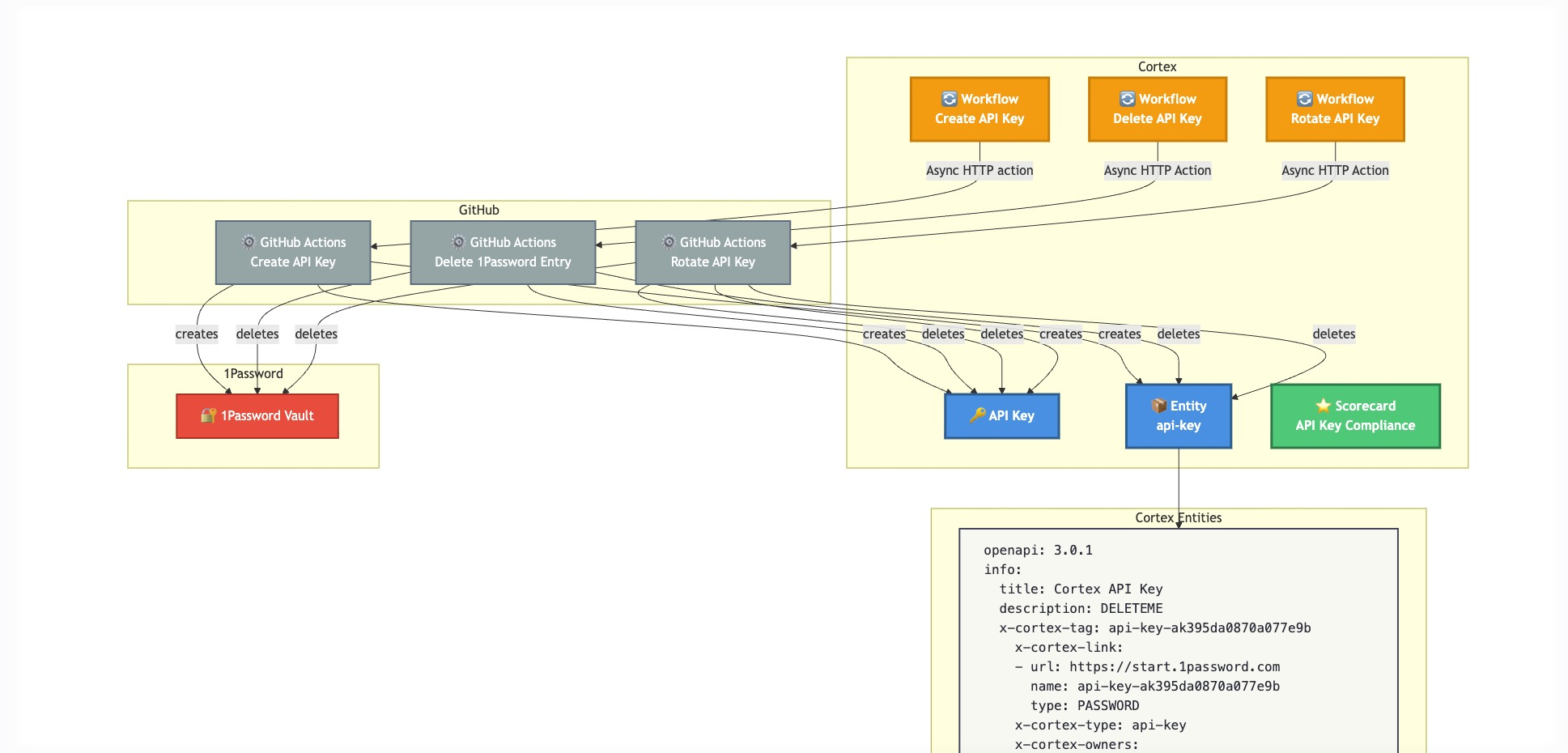
I ended up building this solution and think it’s really cool. It’s just not needed based on how we are currently using these API keys.
The summary of this original design:
It uses a custom entity named api-key
API keys are created via a Cortex Workflow, enforcing name, description and expiration date fields
The Cortex Workflow triggers a GitHub Actions Workflow that writes the contents of the API key to a 1Password vault.
Similar Cortex Workflows with corresponding GitHub Actions are created for deleting and rotating an API key.
Custom Events are written to the api-key entity when the key is created or rotated.
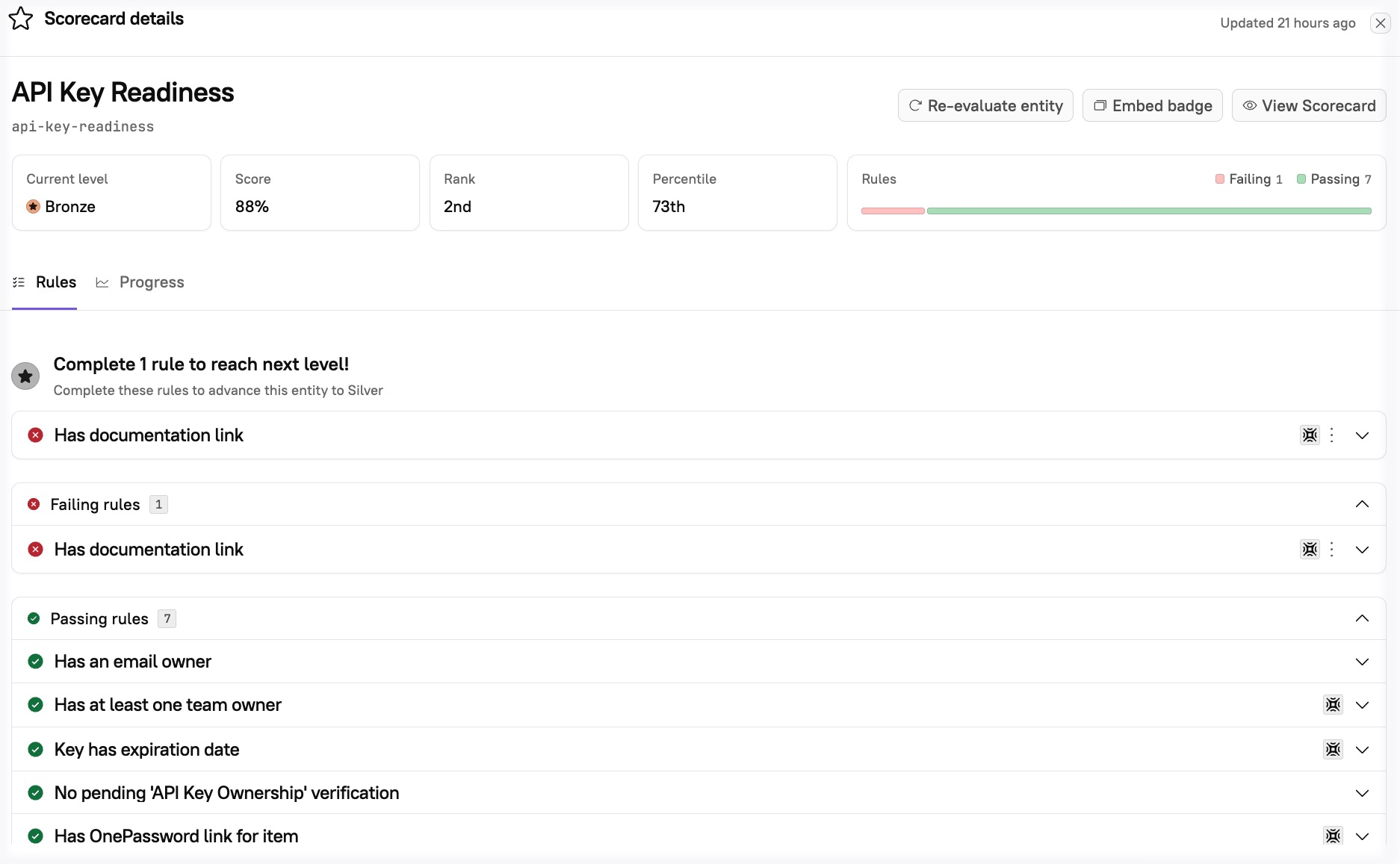
A Scorecard checks api-key entities for documentation, expiration date, rotation date and owners
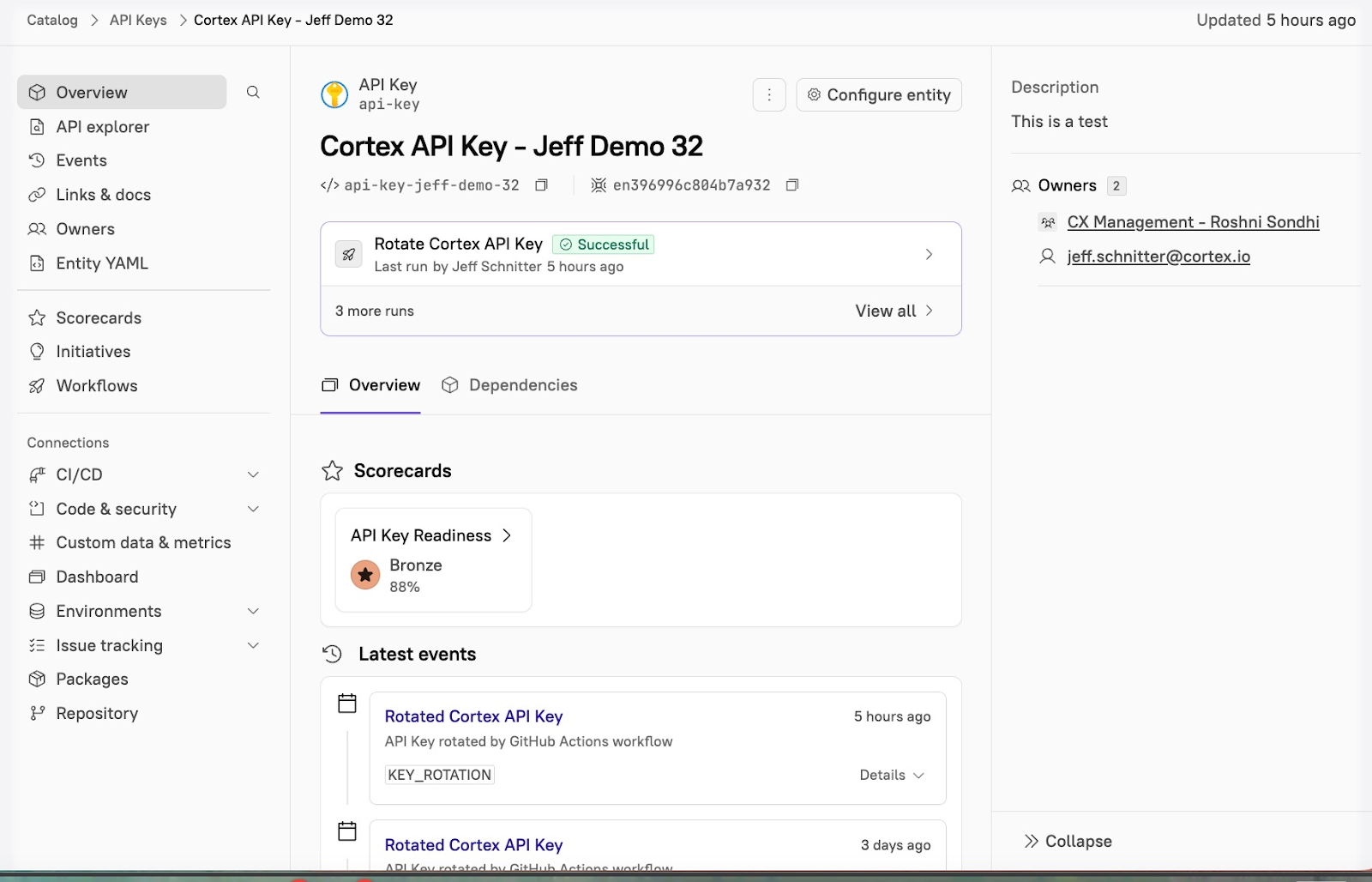
Sample API key entity:
API Key Readiness Scorecard:
Step 3: Build a lot of cool things, get frustrated, learn and reflect
I spent several afternoons building the complex solution. The amount of time I was investing should have been a warning that this solution was too complex. I kept plugging away thinking that the final solution could easily be shared with others, so the heavy initial investment would be solving the problem in the first place.
Beaming with a big grin on my face, I showed Cristina Buenahora Bustamante, one of our founding engineers, the solution I created. She said something to the effect of “That’s cool, but I wonder if it’s too complex for managing API keys.”
I let that comment sit in the back of my head while I continued to toil. Once completed, I started thinking about “selling” this solution to our engineers and other users who create API keys in our production tenant.
I realized that I couldn’t. It was too complex.
Back to the design board, this time keeping in mind “Everything should be as simple as possible and no simpler.”
Step 4: Simplify with a shell script and a data verification
Now for the tale of the second solution. Apologies for the frenetic mixing of Halloween and Dickens metaphors in this recipe. I make no promises about cleaning up this abuse of the English language in future recipes. I’m an engineer, after all.
Simple for me usually comes back to my technical love language, BASH scripts.
I created a shell script that makes a call to the Cortex Command Line Interface (CLI) to list all API keys. I was able to form my CLI command to return data in comma-separated valued (CSV) format with only the columns I needed.
#!/usr/bin/env bash
#
# This script loops over a list of Cortex API keys and creates custom api-key entities. The owner is left blank and must be edited manually.
set -e
tenant="cortex"
IFS=$'\n'
#
# Define various files; ensure software pre-requisites are met.
#
function check_setup() {
echo "verifying software pre-requisities"
build_directory="build"
if [ ! -d ${build_directory} ]
then
mkdir -p ${build_directory}
fi
which cortex > /dev/null || (echo "missing cortex utility"; exit 1)
}
#
# Create Cortex api-key entities from list output of cortex api-keys.
#
function create_entities() {
while IFS=, read -r cid name description createdDate expirationDate
do
kebab=$(echo "$name" | tr '[:upper:] ' '[:lower:]-')
tag="${kebab}"
echo " cid = $cid"
echo " name = $name"
echo " kebab = $kebab"
echo " description = $description"
echo " createdDate = $createdDate"
echo " expirationDate = $expirationDate"
echo "tag = $tag"
export TAG=${tag}
export CID=${cid}
export TITLE=${name}
export DESCRIPTION=${description}
export CREATED_DATE=${createdDate}
export EXPIRATION_DATE=${expirationDate}
file=${tag}.yaml
envsubst < entity.tmpl > build/${file}
done < <(cortex -t ${tenant} api-keys list --csv --no-headers -C cid -C name -C description -C createdDate -C expirationDate)
}
#
# Main
#
check_setup
create_entities
Custom api-key entities were created using a text file template as a guide.
$ cat entity.tmpl
openapi: 3.0.1
info:
title: ${TITLE}
x-cortex-tag: ${TAG}
description: ${DESCRIPTION}
x-cortex-type: api-key
x-cortex-owners:
- type: EMAIL
email: TODO
x-cortex-custom-metadata:
apiKeyCid: ${CID}
createdDate: ${CREATED_DATE}
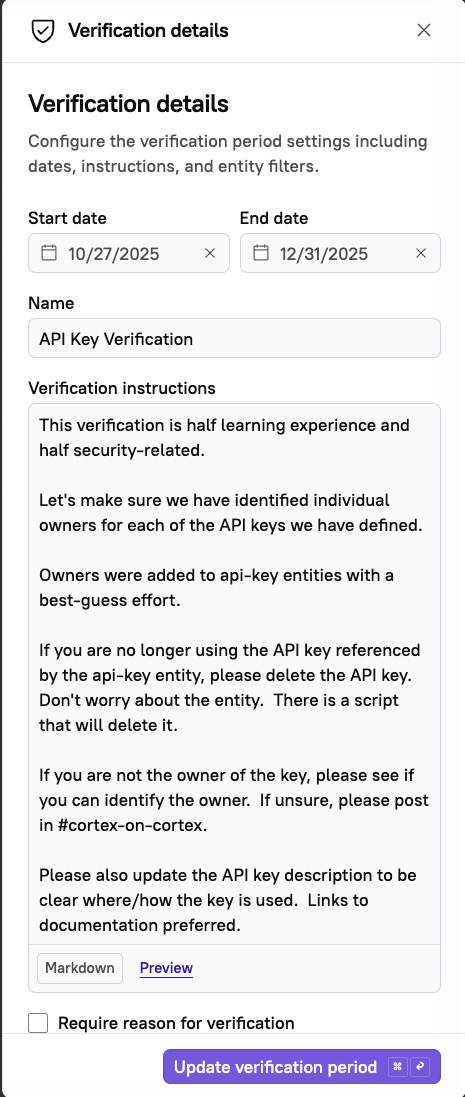
expirationDate: ${EXPIRATION_DATE}I wanted to create a Data Verification period to get proper ownership and documentation created, but this was a Catch-22. In order to have someone verify the content I needed to have an owner defined for the custom entities.
My left brain was screaming “You have to create some automation to solve this”. My right brain is laid back, and is willing to wait for the left brain to scream hoarse. Right brain says “There are only 9 keys and you own one of them, so just make a best guess as to who owns the other 8 and then create your data verification. A little manual work here will cost far less than an over-engineered solution”.
And this became the solution, a small shell script with a couple of manual edits for best-guess owners.
I ran this one-liner to add the newly-created api-key entities to our Cortex instance using the CLI:
for file in `ls -1`; do echo "file = $file"; cortex catalog create -f ${file}; doneI then created a Data Verification period, asking api-key owners to update the API key description to include details of the owner and how the key is used.
Conclusion
I had a ton of fun working on this recipe even though the final product did not include a lot of what I built.
A couple of key learnings:
If you have words to live by, then you better adhere to them

Cortex is so powerful that I tricked myself into thinking I needed a complex solution just because I could build one. One of Cortex’s key principles is that it reduces developer friction. It’s important that you don’t build solutions in Cortex that introduce friction. Cortex Workflows and GitHub Actions Workflows need to be maintained. There is a cost to building them.
I expect Cortex to evolve over time and wouldn’t be surprised if API keys become an built-in entity type in the future. If and when this day comes, I may revisit my complex solution because much of it may be encapsulated in the core platform, making the complex more mundane.
Don’t be afraid to walk away from a solution after investing a lot of time and thought into it. The right solution in this case was the simpler solution.
1Password is a good password manager for simple dev automation secrets
I ended up spending some time getting to know and like 1Password. I modified all of my team’s GitHub Action Workflows to pull secrets from 1Password. When secrets are added in GitHub it’s unclear where they came from and who owned them. Now, they are clearly defined in 1Password and they can be updated at any time and the automation will continue to work.
If you end up using 1Password in your automation scripts, be sure to read this post about 1Password’s management of stdin from automated scripts.
The TL;DR from me is: add < /dev/null to the end of each of your op CLI calls to prevent the error: “invalid JSON in piped input”.
I still think there is room to leverage a password manager and your Cortex API keys.
There’s a Cortex Academy Course for that
I feel like there will always be one or more Cortex Academy courses worth taking that provide insights into these recipes.
The final solution for this recipe resulted in a new catalog named API keys and a Data Verification period created to ensure owners of the keys were identified.
Check out Introduction to Catalogs and Cortex Solutions: Production Readiness, which covers Data Verification, to learn more about these topics.
Happy Cooking! 👨🍳👩🍳
Cortex Kitchen is a series where we share practical recipes for building, deploying, and maintaining solutions in Cortex.
About the author
I don’t like to cook, so this is an apology to my wife, Debbie, who is an amazing cook. The irony of me using a chef metaphor for this blog is not lost on anyone and will be the source of well-deserved razzing in my home. When it comes to the kitchen, I am good at washing dishes and chopping vegetables.


