
Today's Recipe: Vibe-coding an identity-provider integration for Cortex
Time: 3 hours
Difficulty: Medium
Serves: Your entire IDP
What We're Cooking
In this recipe, we’ll explore setting up an identity provider integration for Cortex when your source of truth for teams does not come from one of Cortex’s built-in integrations. We’ll vibe-code an integration to import users, teams, and the team hierarchy from Lattice to Cortex.
Ingredients
1 Lattice API key
1 Cortex API key with Catalog access
1 GitHub account with ability to run Actions
1 AI-powered Chatbot - we’ll be using claude.ai
A dash of python knowledge
A dash of GitHub Actions knowledge
Preparation Steps
Step 1: Identify the business problem you are trying to solve
Cortex, the company, needs a reliable source of truth for teams automatically ingested into Cortex, the app.
Cortex’s source of truth comes from two primary sources:
HR data from Rippling
GitHub teams
We use the GitHub integration to import teams, but this only solves the problem for team ownership for entities that are managed in code. We create entities for all sorts of things – customers, assets, etc and not all are owned by a GitHub-managed team.
Step 2: Explore the interfaces providing the data
I didn’t have access to the Rippling API, so I leveraged Lattice, which pulls in data from Rippling and exposes it via their API.
I’m old-school, so I just ran a handful of curl calls to understand how the APIs worked and what data they returned.
These were as simple as:
$ cat departments.sh
#!/usr/bin/env bash
curl https://api.latticehq.com/v1/departments \
-H "Authorization: Bearer ${LATTICE_API_KEY}"
$ cat users.sh
#!/usr/bin/env bash
curl https://api.latticehq.com/v1/users \
-H "Authorization: Bearer ${LATTICE_API_TOKEN}"I saw that these calls returned ten items, so I just needed to verify how pagination worked.
Using a cursor from the user API, I was able to verify a paginated call:
$ cat users-cursor.sh
#!/usr/bin/env bash
curl "https://api.latticehq.com/v1/users?startingAfter=*kOQ==" \
-H "Authorization: Bearer ${LATTICE_API_KEY}"Step 3: Identify the tools and technology you want to use to solve the problem
If I had access to a production-grade kubernetes cluster, I’d consider using an Axon relay integration. Since I don’t, I decided to leverage technology I was comfortable with, namely python and GitHub Actions.
Step 4: Sketch out a design
I love graphing tools as code. My current preferred tool is Mermaid.
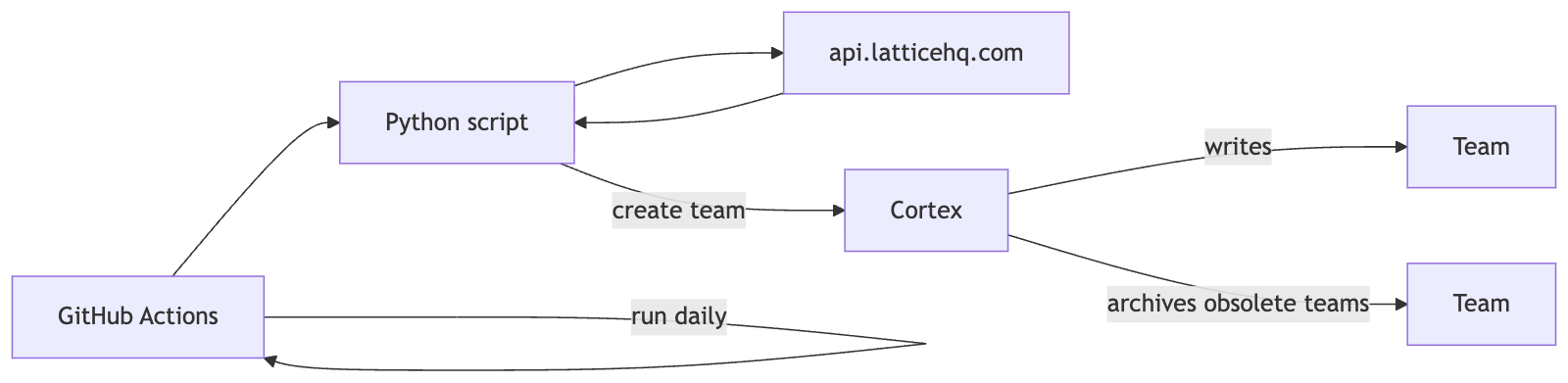 Mermaid code for the above diagram:
Mermaid code for the above diagram:
```mermaid
flowchart LR
PY[Python script]
GHA[GitHub Actions]
API[api.latticehq.com]
CORTEX[Cortex]
TEAM[Team]
OBSOLETE[Team]
GHA --> PY
PY --> API
API --> PY
GHA -->|run daily| GHA
PY -->|create team| CORTEX
CORTEX -->|writes| TEAM
CORTEX -->|archives obsolete teams| OBSOLETE
click GHA "https://github.com/cortexapps/customer-experience/actions/workflows/lattice.yml" "View GitHub Actions"
click PY "https://github.com/cortexapps/customer-experience/blob/master/projects/lattice/lattice-to-cortex.py" "View Python Script"
click CORTEX "https://app.getcortexapp.com/login?tenantCode=cortex-cx" "cortex-cx workspace"
```Step 5: Initial prompt to claude.ai
I only became aware of the term vibe coding in the last month or two. This makes sense given that the term was coined in February 2025.
I used Claude to vibe code the integration and started with this prompt:
Ready to vibe code to use the Lattice API to generate teams that can be imported into Cortex?
The goal is to generate team YAML files of this format:
openapi: 3.0.1
info:
title: name
x-cortex-tag: slug
x-cortex-team:
members:
- name: Firstname Lastname
role: null
email: email@cortex.io
description: title
notificationsEnabled: false
metadata:
summary: Automatically imported from custom Lattice integration
department: false
x-cortex-type: team
x-cortex-slack:
channels:
- name: engineers
notificationsEnabled: true
x-cortex-children:
- tag: cortexapps-engineering
- tag: design
- tag: productWe will rely on these two APIs from lattice:
The departments API returns a response like this:
{
"id": "department-1234",
"object": "department",
"url": "/v1/department/department-1234",
"name": "Customer Engineering - Support",
"description": null,
"createdAt": 1733944030
},We will use the name attribute to populate the team title. Convert the name attribute to kebab case and use that for the x-cortex-tag of the team.
The users API returns a response like this:
{
"id": "user-1234",
"object": "user",
"url": "/v1/user/user-1234",
"manager": {
"id": "user-5678",
"object": "user",
"url": "/v1/user/user-5678"
},
"directReports": {
"object": "list",
"url": "/v1/user/user-1234/directReports"
},
"department": {
"id": "department-abc",
/v1/department/department-abc
"object": "department",
"url": "/v1/department/department-abc"
},
"name": "Jeff Schnitter",
"preferredName": "Jeff",
"email": "jeff.schnitter@cortex.io",
"tasks": {
"object": "list",
"url": "/v1/user/user-1234"
},
"title": "Solution Architect",
"status": "ACTIVE",
"startDate": "yyyy-mm-dd",
"birthDate": "yyyy-mm-dd",
"timezone": "America/Los_Angeles",
"gender": "Male",
"isAdmin": false,
"externalUserId": null,
"createdAt": 1719004428,
"updatedAt": 1757710831,
"customAttributes": {
"object": "list",
"url": "/v1/user/user-1234/customAttributes"
}
}Use name, email and title to populate the name, email, and description fields in the x-cortex-members block of the team. Set the role to 'manager' if the user is a manager, otherwise set it to null.
This is what a sample team entity will look like:
openapi: 3.0.0
info:
title: Team Ganesh Datta
x-cortex-tag: executive-ganesh-datta
x-cortex-type: team
x-cortex-groups:
- lattice
x-cortex-children:
- tag: product-kara-gillis
type: team
x-cortex-team-members:
- name: Ganesh Datta
role: member
email: ganesh.datta@cortex.io
description: ManagerUse the relationships in the user and departments objects to determine the hierarchy, which will allow you to determine the x-cortex-children values for each team. These will be the team slugs for any dependent teams in the hierarchy.
Build this as a python script.
As a first pass, first retrieve all users and all departments and save the content in files named users.json and departments.json. If these files exist on disk, do not use the API to retrieve them unless a 'force' parameter is used in the script. This way I don't need to make unnecessary API calls while developing the script.
Got it?
Pseudo code:
get all users and save to users.json
get all departments and save to departments.json
determine best strategy to loop over data to reconstruct team YAML files
save the team YAML files to disk; do not (yet) try to use the Cortex API to add them to Cortex
Step 6: Iterate
Claude did a great job on the first pass of the script. It took another 20 or so prompts to land on the final product.
Examples:
It's not safe to pass an API token on the command line. Please change to retrieve as an environment variable named LATTICE_API_TOKEN. If the variable is not set, fail with an appropriate error message.
Is there something wrong with the pagination logic? Looks like we were hitting the same cursor endpoint multiple times.
For pagination, the query parameter is 'startingAfter' not 'cursor'.
I eventually got to the point where I felt like I could make the last couple of minor tweaks. It was helpful for me to get into the code a bit to ensure I’d be able to maintain it going forward.
Step 7: Test
One of the things I wanted to test was archiving. The script compares a list of all teams retrieved from Lattice with teams previously imported by Lattice. I have seen transitory problems with integrations that result in all teams getting archived because none were found when querying the API, so I added a threshold where the script will fail if it is going to attempt to archive more than 25% of the teams.
I ran some manual tests to confirm it was working as I expected. I was ready for the final step.
Step 8: Automate
I went back to Claude and asked it to generate a GitHub Actions workflow to run the script daily. I really only needed the cron expression because I had a similar python GitHub Actions workflow I was able to use as a starting point.
name: Team Import from Lattice
on:
schedule:
# Run daily at 8 am UTC (cron: minute hour day month day-of-week)
- cron: '0 8 * * 1-5'
workflow_dispatch: # Allow manual triggering for testing
env:
CORTEX_API_KEY: ${{ secrets.CORTEX_API_KEY }}
LATTICE_API_TOKEN: ${{ secrets.LATTICE_API_TOKEN }}
jobs:
create-teams:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.11'
- name: Install dependencies
run: |
pip install requests pyyaml
- name: Generate teams
run: |
python3 ./projects/lattice/lattice-to-cortex.pyConclusion
As a Solution Architect, it helps me to build things that I recommend to our customers. It took about 3 hours to build this integration starting with me knowing nothing about the Lattice API to having an automated workflow running in GitHub.
I recommend sticking to technologies with which you are familiar because it will help you know when to challenge your AI agent.
You, too, can follow this outline to help build an integration with Cortex. If you need to hone your Cortex skills, make sure to check out Cortex Academy.
Happy Cooking! 👨🍳👩🍳
Cortex Kitchen is a series where we share practical recipes for building, deploying, and maintaining solutions in Cortex.
About the author
I don’t like to cook, so this is an apology to my wife, Debbie, who is an amazing cook. The irony of me using a chef metaphor for this blog is not lost on anyone and will be the source of well-deserved razzing in my home. When it comes to the kitchen, I am good at washing dishes and chopping vegetables.


