
2021 was a great year for Cortex in many ways:
We raised our Series A.
We tripled our team size.
We launched several new projects!
We grew our monthly active users (MAUs) by 10x.
But as any startup company (and especially engineering team) would tell you, scaling a product and an organization puts new demands on both your processes and your infrastructure.
In this series, we’ll be highlighting lessons we’ve learned in the past year, with a focus on two things: 1) how we scaled our infrastructure to handle a massive uptick in customers, and 2) how we introduced key process changes to help manage complexity while growing our engineering team.
This first post will focus on our infrastructure: namely, how we cut our Postgres RPS (Requests Per Second) by over 50% with a single change. It assumes a working knowledge of Spring, Spring Data, and Hibernate.
Problem
As we grew our userbase, we began to run into some performance issues, primarily bottlenecked by our upstream Postgres database. Our RPS went over 180 (from < 50) in just a few months, and we started running into problems like SQL connection timeouts, dropped connections, and significantly increased latency. This led to a degraded customer experience, which was unacceptable.
So, we set to work investigating how we could iron out these Postgres bottlenecks. We quickly realized that we were spending way too many cycles making database writes, which was clogging up the system. Each write to Postgres was a single call 😱, meaning that if we wanted to save 50 rows to the database, instead of doing a single SQL call to save all these 50 rows, we’d make 1 call per row!
Root Cause: Using IDENTITY for id value generation in Hibernate
Why weren’t we able to make a batch update? As it turned out, the problem had to do with how we were using Hibernate to generate identifier values (AKA primary keys) for the entities in our database.
The approach we were using involved retrieving values from the IDENTITY columns that Hibernate dynamically maintains as new entities are inserted into the database. Our writes to the DB for new resources were done without specifying the id (primary key), and instead used GenerationType.IDENTITY.
Here’s what our Spring entity looked like:
@Entity
@Table(name = "entity")
data class Entity(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long? = null,
val metadata: String,
) : TenantEntity()>With this strategy, it was incredibly simple to use the ORM to both create and update existing resources:
If an id isn’t passed, a new row will be created.
If an id is passed, the existing row will be updated.
Sounds straightforward, right? We thought so too! And it seemed to work well — until we realized that using IDENTITY introduced a major performance issue. The downside of this strategy is that batch updates won’t work, as documented here.
This posed a big problem for us, because all our entities used IDENTITY identifier value generation. For each of our existing tables and their corresponding entities, we’d have to swap our strategy from IDENTITY to a different one that would support batch insert statements.
Migrating from IDENTITY to sequence-based id generation
Upon investigating other generation types we could use for our entities that would support batching, we came across Hibernate’s sequence-based identifer value generation. This strategy is backed by an underlying database sequence. Hibernate will request the next available id from the sequence to get the new id for the resource.
While the underlying mechanics of this strategy is beyond the scope of this article, the bottom line is that this sequence-based strategy would enable batch inserts for us!!
Now we needed to figure out how to migrate from our existing IDENTITY strategy to the new sequence-based approach.
Upon investigating this further, we realized that our existing tables already had a Postgres sequence. So if we had a table defined like so:
CREATE TABLE IF NOT EXISTS entity (
id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
...
)…a sequence with the name entity_id_seq would be created!
You can run the following SQL command to check the existence of the sequence:
SELECT
*
FROM
pg_sequence
WHERE
seqrelid = 'entity_id_seq'::regclass;Since we were able to easily access the sequence for our Postgres tables, we could make a very localized change to switch over to using the sequence-based strategy for id generation.
For each entity, we only had to change a few lines of code to solve our performance bottleneck. An updated entity looks like this:
private const val TABLE = "entity"
private const val SEQUENCE = "${TABLE}_id_seq"
@Entity
@Table(name = TABLE)
data class Entity(
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = SEQUENCE)
@SequenceGenerator(name = SEQUENCE, sequenceName = SEQUENCE, allocationSize = 50)
@Column(name = "id")
val id: Long? = null,
val metadata: String,
) : TenantEntity()AllocationSize and Sequence Increment Size
One thing to note here is that the allocationSize property in Hibernate needs to be the same as the increment size for the underlying sequence in Postgres.
This is so that Hibernate and the underlying sequence don’t go “out of sync” in terms of the ids that they’re holding. This also prevents any issues with a distributed architecture where multiple servers are writing to the same table.
By default, the increment size for our Postgres sequences was 1. We wrote a very quick migration to change it to match our allocationSize:
ALTER SEQUENCE entity_id_seq INCREMENT 50;
Now, Hibernate will only need to make 1 call to get the list of ids per 50 inserts.
And it’ll only need 1 call to insert those 50 rows as well 🙂
Conclusion
Here’s a summary of what we learned from this issue:
With Hibernate, start using database sequence-based identity value generation as soon as possible — especially if you foresee the number of writes increasing.
Keep the allocationSize and the underlying Postgres sequence increment size params the same to avoid id collisions and support a distributed system.
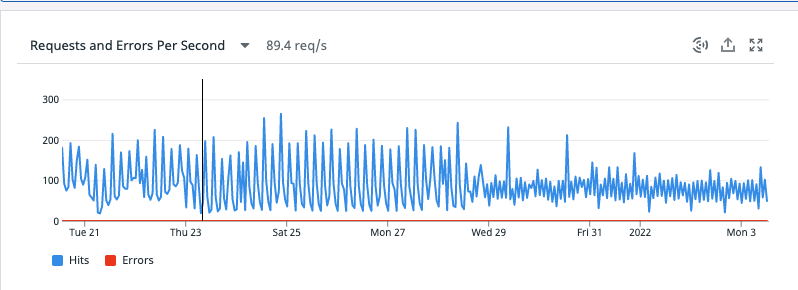
Finally, here’s a screenshot of our RPS going from near 180 to about 90 after we implemented this change.
If you want to explore these topics further, you’ll find these resources useful:
And if you have any further technical questions about how we made this migration happen, please reach out to me personally at aditya.bansal@cortex.io!


